比较 BentoML 和 Vertex AI:为 AI 模型部署做出明智决策
2025 年 2 月 7 日 • 作者:张先先 和 Sherlock Xu
随着对 AI 应用的需求不断增长,将 AI 模型部署到生产环境中需要仔细考虑。在这篇博文中,我们比较了这方面的两个平台:Vertex AI 和 BentoML。Vertex AI 作为 Google Cloud 生态系统的一部分,提供了一套全面的工具,涵盖从训练到部署的整个 ML 生命周期。而 BentoML 则是一个统一推理平台,用于使用任何模型在任何云上构建和扩展 AI 系统。
然而,仅凭定义不足以了解全貌。为了帮助 AI 团队做出明智决策,我们对这两个平台进行了一些研究和测试。我们的分析涵盖模型部署的三个关键领域
- 云基础设施
- 扩展和性能
- 开发者体验
现在让我们深入探讨。
云基础设施
在生产环境中部署 AI 模型时,需要考虑几个关键的基础设施因素。
多云支持
能够在多个云服务提供商 (CSP) 之间部署模型,确保了灵活性,并防止了云厂商锁定。它允许 AI 团队根据他们对 成本、性能或地理位置 的特定需求来选择最佳提供商。
BentoML 支持在各种云提供商上部署,而 Vertex AI 自然只局限于 Google Cloud 生态系统。
GPU
AI 工作负载,尤其是大型语言模型 (LLM),高度依赖 GPU(甚至 TPU)来实现高性能推理。灵活的基础设施应允许 AI 团队根据可用性、定价和性能要求选择最佳的 GPU。
-
GPU 可用性和定价
- BentoML 支持任何云提供商的任何 GPU 类型。它使用户能够为各种推理工作负载选择不同的 GPU,从而实现最佳的成本性能比。
- Vertex AI 仅限于 GCP 上可用的 GPU,GPU 定价受 GCP 定价结构的约束。
-
GPU 云支持:
- BentoML 允许来自专业 GPU 云提供商(如 Lambda Labs 和 CoreWeave)的 GPU 加入并提供模型服务。
- Vertex AI 仅支持 Google Cloud 内可用的 GPU。
安全性和合规性
对于企业,尤其是在受监管行业中的企业,安全合规性是不容商榷的。您必须确保您的平台遵循严格的数据隐私和安全标准,以降低风险并满足监管要求。
BentoML 和 Vertex AI 都符合 SOC2 标准,并支持私有 VPC AI 部署。
以下是云基础设施的高层级比较
| 项目 | BentoML | Vertex AI |
|---|---|---|
| 多云支持 | AWS、Azure、GCP 等。 | 仅限 GCP |
| GPU 可用性 | 任何 CSP 或 GPU 云的任何 GPU 类型 | 仅限 GCP 上可用的 GPU |
| GPU 定价 | 使用在任何地方定价最有竞争力的 GPU | 受 GCP 定价约束 |
| GPU 云支持 | Lambda Labs、CoreWeave 等。 | 不支持 |
| TPU 支持 | 是 | 是 |
| SOC2 合规性 | 是 | 是 |
| 在私有 VPC 中部署模型 | 是 | 是 |
扩展和性能
缓慢的扩展可能导致延迟增加和吞吐量降低。这不仅影响用户体验,还会显著增加成本。这是因为 AI 团队在扩展事件期间通常需要过度配置资源以保持可接受的性能。
扩展指标
Vertex AI 实施基于资源利用率的自动扩展,根据 CPU 和 GPU 利用率等指标调整副本数量。然而,对于 LLM 工作负载,即使 GPU 未完全饱和,也可能显示高利用率。这种效率低下可能导致不准确的扩展,从而在峰值负载下引起延迟尖峰和吞吐量下降。
BentoML 采用基于并发的自动扩展,它根据活跃请求(无论是在队列中还是正在处理)来扩展副本。此指标
-
精确反映系统负载
-
使用扩展公式准确计算所需的副本
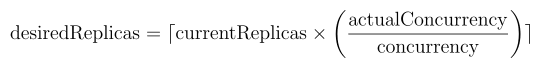
-
易于根据简单的负载测试进行配置
高级扩展功能
与 Vertex AI 相比,BentoML 提供了一些高级扩展功能
-
缩减至零 (Scale-to-zero): BentoML 允许实例在空闲时关闭,通过仅在使用资源时才消耗资源来提高成本效率。
-
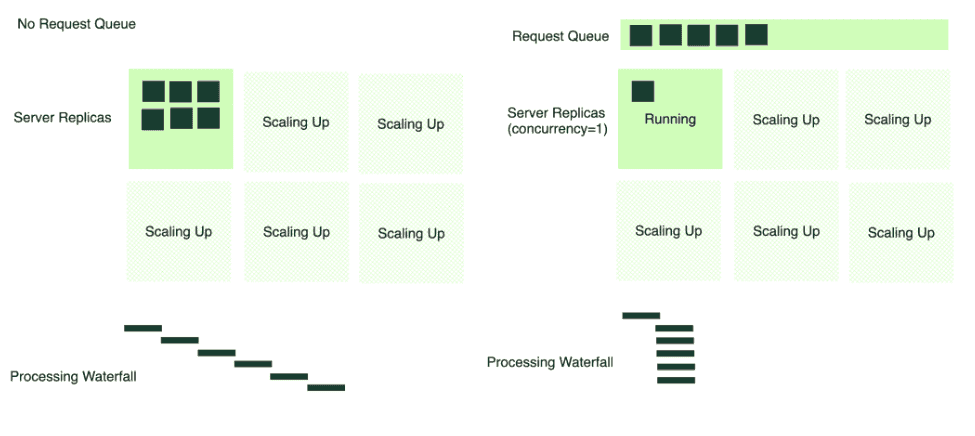
请求队列 (Request queue): BentoML 支持在将传入请求分派到服务实例之前对其进行排队。这可以防止服务器在流量高峰期间过载,最大化请求成功率,并优化自动扩展的有效性。
-
备用实例:
- Vertex AI 允许用户预配置资源池来处理峰值流量负载并减少冷启动时间。
- BentoML 允许用户预配置云机器,使实例保持“温热”状态,随时准备处理突发的需求激增。备用实例在扩展期间可由所有已部署的模型共享。
-
自定义稳定窗口 (Custom stabilization windows):用户可以精确控制系统向上或向下扩展的积极程度,以实现最佳效果。
-
异步任务 (Async tasks):对于需要长时间计算的 AI 模型,异步任务允许在后台处理工作负载,并在之后检索结果。这对于处理文档处理或批量推理等用例非常有用。
欲了解更多信息,请参阅按您期望的方式扩展 AI 模型。
冷启动性能
在我们使用 A100 GPU 对 Llama 3.1 8B 进行的负载测试中,我们观察到两个平台之间存在显著差异
- Vertex AI 启动一个副本需要 148 秒。
- BentoML 在 71 秒内启动一个副本,由于 BentoCloud 上的优化,速度几乎是前者的两倍。
以下是扩展和性能的高层级比较
| 项目 | BentoML | Vertex AI |
|---|---|---|
| 自动扩展 (Autoscaling) | 基于请求并发 | 基于资源利用率 |
| 缩减至零 (Scale-to-zero) | 是 | 否 |
| 扩展行为 | 自定义稳定窗口 | 否 |
| 请求队列 | 是 | 否 |
| 冷启动时间 | 71 秒 | 148 秒 |
| 备用实例 | 是 | 是 |
| 异步任务 | 是 | 否 |
开发者体验
开发者体验直接影响 AI 团队将模型从开发阶段快速推向生产环境的速度。更顺畅的工作流程可以降低复杂性,加速迭代,并更容易优化推理性能。
预封装模型
BentoML 和 Vertex AI 都提供了多种预封装模型,便于轻松部署,例如 DeepSeek、Llama 和 Stable Diffusion 模型系列。
自定义模型推理
平台如何处理模型推理和部署是影响开发者生产力的关键因素
-
BentoML 让开发者完全专注于在 Python 中定义模型服务逻辑,无需担心 Docker 镜像。它会自动执行以下操作
- 打包源代码和环境规范
- 构建符合 OCI 标准的镜像
- 在 BentoCloud 上部署镜像
-
Vertex AI 也支持 Python 推理代码,但它要求开发者手动处理容器化,包括
- 使用 Docker(或其他类似工具)打包代码和环境
- 将容器镜像上传到 Google Artifact Registry (GAR)
- 根据 Vertex AI 要求配置部署规范
这个手动过程需要更深入的 Docker 知识,并增加了将模型推向生产环境所需的时间。BentoML 简化了这一过程,只需几分钟即可实现从开发到生产的过渡,而 Vertex AI 可能需要数小时。
LLM 推理
大型语言模型 (LLM) 推理需要精细调整的优化,以平衡延迟、吞吐量和成本效率。
-
自定义推理后端 (Custom inference backends)。 为 LLM 服务选择正确的推理后端至关重要。它允许开发者根据其用例做出正确的权衡,以最大化性能。例如
- 对于在线应用,您可以通过牺牲吞吐量来优先考虑较低的延迟。
- 对于批量应用,重点通常会转移到以延迟为代价实现更高的吞吐量。
这两个平台都支持流行的推理后端,如 vLLM、TRT-LLM 和 SGLang。BentoML 社区提供了可直接使用的示例,您可以直接部署或根据需要进行自定义。Vertex AI 也支持这些后端,但要求开发者根据其规范配置自定义 Docker 镜像。
-
兼容 OpenAI (OpenAI-compatible)。 BentoML 支持兼容 OpenAI 的端点。这对于希望与依赖 OpenAI API 架构的应用集成的团队至关重要。然而,Vertex AI 对请求的输入格式有严格限制,并通过统一的服务 URL 公开服务。这使得提供 OpenAI API 兼容性变得困难。
开发沙箱
BentoML 提供 Codespaces,一个云开发环境,允许开发者
- 连接他们喜欢的 IDE 以进行无缝开发
- 访问强大的云 GPU(如 A100)进行推理
- 通过在 BentoCloud 上立即反映的更新进行调试并查看实时日志
- 在开发和生产环境之间实现一致的行为
欲了解更多信息,请参阅使用 BentoML Codespaces 加速 AI 应用开发。
多模型流水线
现代 AI 应用,例如 RAG 和 AI Agent,通常需要多模型工作流程,其中多个模型协同工作来处理和生成结果。
BentoML 使用服务 API (Service APIs) 简化了多模型编排,允许开发者
- 按顺序运行模型:一个模型的输出直接作为另一个模型的输入传递。
- 并行运行模型:多个模型同时处理数据。
欲了解更多信息,请参阅多模型组合 (multi-model composition) 和分布式服务 (distributed Services)。
可观测性
有效的可观测性有助于监控和优化模型性能及基础设施使用情况。
与 Vertex AI 相比,BentoML 提供了额外的可观测性功能,包括 LLM 特定的性能指标,如首个 Token 延迟和前缀缓存命中率。
以下是开发者体验的高层级比较
| 项目 | BentoML | Vertex AI |
|---|---|---|
| 预封装模型 | 是(预构建的 Bento) | 是(模型园) |
| 自定义模型推理 | Python 推理代码 |
|
| 从开发到生产 | 分钟 | 小时 |
| LLM 推理 |
| 难以自定义 |
| 开发沙箱 | Codespaces | 不支持 |
| 多模型流水线 | 是 | 否 |
| 可观测性 | 指标
日志
| 指标
日志
|
根据您的需求选择合适的平台
Vertex AI 和 BentoML 之间的正确选择取决于您的具体需求和用例。
何时选择 Vertex AI
Vertex AI 特别适用于以下组织
- 需要一个端到端的 ML 平台用于训练、微调和部署
- 在 GCP 生态系统中投入巨大,并需要与其他 GCP 服务无缝集成
- 拥有成熟的 DevOps 团队,熟悉容器管理
何时选择 BentoML
如果您符合以下条件,BentoML 是更好的选择
- 主要关注模型服务和部署效率
- 需要多云灵活性
- 希望最大限度地缩短从开发到生产的时间
- 想要一个无需 Docker 的工作流程,以加快迭代速度
- 需要更好的冷启动性能和缩减至零的能力
- 对于 RAG、AI Agent 或自定义工作流程等应用,需要多模型编排和复杂的流水线实现
总结
在做决定时,请考虑您团队的专业知识、现有基础设施和具体用例。这两个平台都在不断发展,增加新功能和能力,以满足生产环境中 AI 部署日益增长的需求。
查看以下资源以了解更多信息