使用 BentoML 部署 ColPali
2025 年 1 月 20 日 • 作者:ILLUIN Technology 和 BentoML
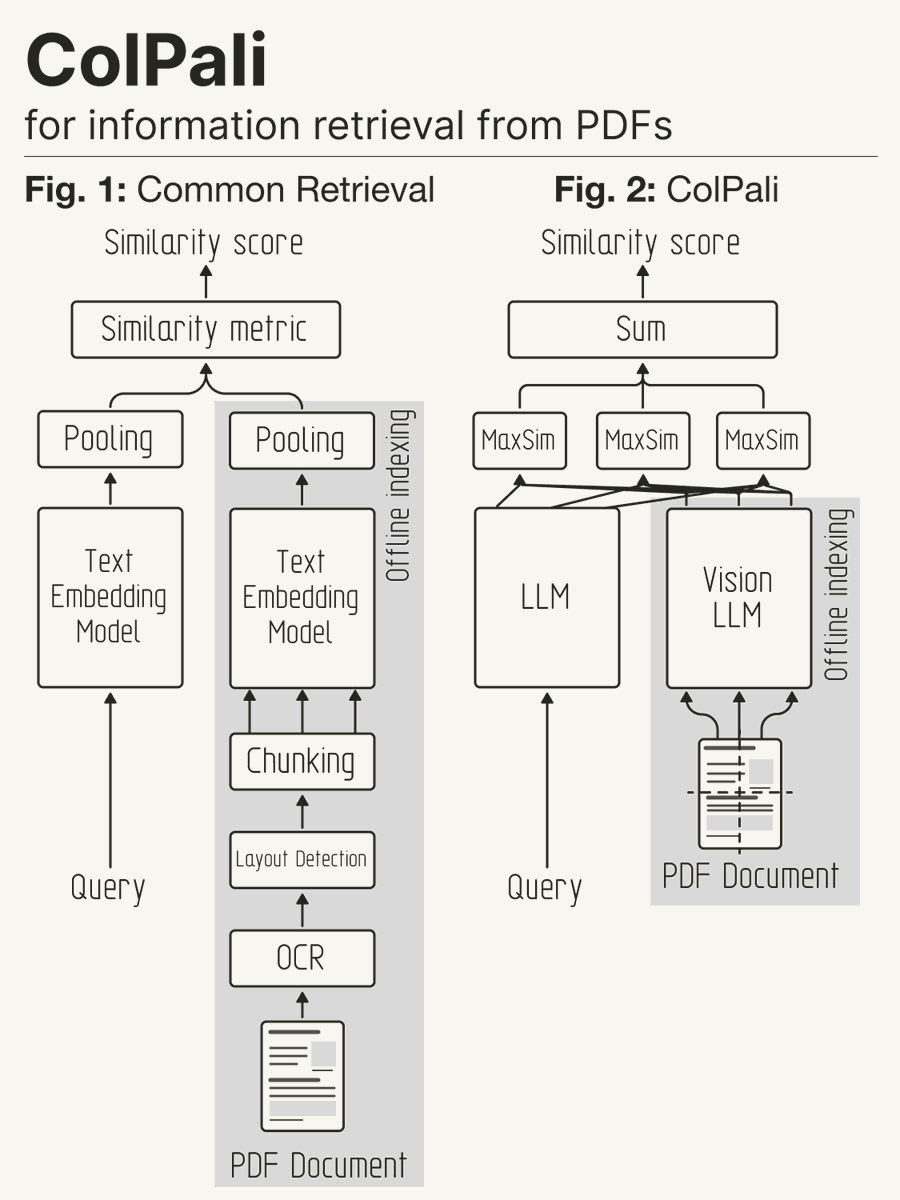
文档检索系统传统上依赖于复杂的文档摄取管道,这通常涉及许多独立的步骤,例如 OCR、布局分析和图表说明。在检索过程中利用视觉元素是一个真正的挑战,需要许多任意选择。如果我们能在提高准确性的同时简化这个过程呢?请看 ColPali,它是一个结合了视觉语言模型 (VLM) 和多向量嵌入能力的模型。
在这篇博文中,我们很高兴分享如何使用 BentoML 部署一个功能齐全的 ColPali 推理 API。它使您能够利用视觉文档嵌入的能力进行大规模文档检索。
什么是 ColPali?
在我们提出的 ColPali 方法中,我们利用 VLM 直接从文档图像(“截图”)构建高效的多向量嵌入,用于文档检索。我们使用 ColBERT 中引入的后期交互方法训练模型,以最大化这些文档嵌入与相应查询嵌入之间的相似性。
使用 ColPali 消除了对可能复杂且脆弱的布局识别和 OCR 管道的需求,只需一个模型即可考虑文档的文本和视觉内容(布局、图表等)。
什么是 BentoML?
BentoML 是一个统一推理平台,用于在任何云上使用任何模型构建和扩展 AI 系统。它包括:
- BentoML 开源服务框架:作为 Python 框架,BentoML 提供推理优化、任务队列、批量处理和分布式编排的关键原语。开发者可以部署任何模型格式或运行时,自定义服务逻辑,并构建可扩展的可靠 AI 应用程序。
- BentoCloud:一个在 BentoML 开源服务框架之上构建的推理管理平台和计算编排引擎。BentoCloud 提供了一个完整的堆栈,用于构建快速可扩展的 AI 系统,具有灵活的 Pythonic API、极速冷启动以及跨开发、测试、部署、监控和 CI/CD 的简化工作流程。
部署 ColPali 的挑战
由于 ColPali 的多向量嵌入方法,高效部署 ColPali 带来了独特的操作挑战。为单个文档页面/图像存储和检索多个向量需要占用大量内存,需要自适应批量策略来优化内存使用。BentoML 通过自适应批量处理和零拷贝 I/O 等功能解决了所有这些挑战,即使对于大型张量数据也能最大限度地减少开销。
为了简单起见,在这篇博文中,我们决定将向量存储在内存中,但对于可扩展的生产环境,强烈建议(如果不是必要)使用向量数据库。ColPali 生成多向量表示来嵌入文档页面/图像(类似于 ColBERT 用于文本嵌入),每个图像块对应一个向量。另一方面,向量数据库传统上每个文档/条目存储一个向量。
目前,有一些向量数据库支持多向量表示,例如 Milvus、Qdrant、Weaviate 或 Vespa。其他数据库,如 Elasticsearch,也正在努力支持此功能。因此,当大规模工业化 ColPali 用于视觉空间检索时,请确保所选的向量数据库能够处理多向量表示。
设置
要开始,首先克隆项目仓库并导航到该目录。它包含部署所需的一切。
git clone https://github.com/bentoml/BentoColPali.git cd BentoColPali
我们建议您设置 Python 虚拟环境以隔离依赖项
python -m venv bento-colpali source bento-colpali/bin/activate
安装所需的依赖项。
# Recommend Python 3.11 pip install -r requirements.txt
下载模型
在运行我们的项目之前,您需要下载并构建 ColPali 模型。由于 ColPali 使用 PaliGemma 作为其 VLM 骨干网络,因此与提供的令牌相关联的 Hugging Face 帐户必须已接受 google/paligemma-3b-mix-448 的条款和条件。
python bentocolpali/models.py --model-name vidore/colpali-v1.2 --hf-token <YOUR_TOKEN>
通过列出您的 BentoML 模型来验证模型下载
$ bentoml models list Tag Module Size Creation Time colpali_model:mcao35vy725e6o6s 5.48 GiB 2024-12-13 03:00:15
使用 BentoML 服务模型
模型准备就绪后,您可以尝试在本地服务模型
bentoml serve .
此命令启动 BentoML 服务器,并在 https://:3000 暴露四个端点
| 路由 | 输入 | 输出 | 描述 |
|---|---|---|---|
| /embed_images |
| 多向量嵌入 | 生成形状为 (batch_size, sequence_length, embedding_dim) 的图像嵌入。 |
| /embed_queries |
| 多向量嵌入 | 生成形状为 (batch_size, sequence_length, embedding_dim) 的查询嵌入。 |
| /score_embeddings |
| 分数 | 计算预先计算的嵌入之间的后期交互/MaxSim 分数。返回形状为 (num_queries, num_images) 的分数。 |
| /score |
| 分数 | 一次性计算图像和查询之间的相似性分数(即按正确顺序运行上面的 3 个路由)。返回形状为 (num_queries, num_images) 的分数。 |
自适应批量处理
在此项目中,我们为 /embed_images 和 /embed_queries 端点启用了 BentoML 的自适应批量处理。此功能根据实时流量模式动态调整批量大小和分派时间,确保资源得到有效利用。您可以使用 max_batch_size 和 max_latency_ms 定义严格的操作限制,保证吞吐量最大化且延迟保持在可接受的范围内。
这是一个配置示例
# Use the @bentoml.service decorator to mark a Python class as a BentoML Service @bentoml.service( name="colpali", workers=1, traffic={"concurrency": 64}, # Set concurrency to match the batch size ) class ColPaliService: ... @bentoml.api( batchable=True, # Enable adaptive batching batch_dim=(0, 0), # The batch dimension for both input and output max_batch_size=64, # The upper limit of the batch size max_latency_ms=30_000, # The maximum milliseconds a batch waits to accumulate requests ) async def embed_images( self, items: List[ImagePayload], ) -> np.ndarray: ...
更多信息,请参阅BentoML 文档和完整源代码。
调用端点 API
要与 API 交互,您可以创建一个客户端向服务器发送请求。下面是一个示例
import bentoml from PIL import Image from bentocolpali.interfaces import ImagePayload from bentocolpali.utils import convert_pil_to_b64_image # Prepare image payloads image_filepaths = ["page_1.jpg", "page_2.jpg"] image_payloads = [] for filepath in image_filepaths: image = Image.open(filepath) image_payloads.append(ImagePayload(url=convert_pil_to_b64_image(image))) # Prepare queries queries = [ "How does the positional encoding work?", "How does the scaled dot attention product work?", ] # Create a BentoML client and call the endpoints with bentoml.SyncHTTPClient("https://:3000") as client: image_embeddings = client.embed_images(items=image_payloads) query_embeddings = client.embed_queries(items=queries) scores = client.score_embeddings( image_embeddings=image_embeddings, query_embeddings=query_embeddings, ) print(scores)
请注意,ImagePayload 需要图像以 base64 编码格式
{ "url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEU..." }
输出示例
[ [16.1253643, 6.63720989], [9.21852779, 15.88411903] ]
部署到 BentoCloud
现在一切都在本地工作正常,是时候将 ColPali 服务部署到 BentoCloud 了。这将为您提供安全、可扩展且可靠的推理 API。
部署之前,请确保通过 @bentoml.service 装饰器在 bentocolpali/service.py 中指定所需的资源。对于此示例,单个 NVIDIA T4 GPU 就足够了
@bentoml.service( name="colpali", workers=1, resources={ "gpu": 1, # The number of GPUs "gpu_type": "nvidia-tesla-t4", # The GPU type }, traffic={"concurrency": 64}, )
登录 BentoCloud。如果您没有 BentoCloud 帐户,请在此免费注册
bentoml cloud login
导航到项目的根目录(bentofile.yaml 所在的位置)。运行以下命令将其部署到 BentoCloud,并可选择使用 -n 标志设置名称
bentoml deploy . -n colpali-bento
部署完成后,您可以在部署 (Deployments) 部分找到它。
要检索暴露的 URL,运行
bentoml deployment get colpali-bento -o json | jq ."endpoint_urls"
将之前客户端代码中的 https://:3000 替换为检索到的 URL,您就可以进行相同的 API 调用了。
默认情况下,部署有一个副本,但您可以根据需要进行扩展。例如,要扩展到 0 到 5 个副本,使用
bentoml deployment update colpali-bento --scaling-min 0 --scaling-max 5
这可以在空闲期间最大限度地减少资源使用,同时以快速冷启动时间高效处理高流量。
结论
在本教程中,我们展示了如何使用 BentoML 部署 ColPali,创建了一个无需复杂 OCR 管道即可理解文本和视觉内容的推理 API。该解决方案易于在本地服务,也可使用 BentoCloud 在生产环境中扩展。快来试试吧,看看它如何简化您的文档处理工作流程!
更多资源