使用 BentoML 部署 Phi-4-reasoning:分步指南
2025 年 5 月 8 日 • 作者: Sherlock Xu
微软最近推出了一系列新的 基于 Phi-4 的推理模型,将高级推理能力引入小型语言模型。其中,Phi-4-reasoning 是一个紧凑的 14B 模型,在复杂推理任务上的表现优于 DeepSeek-R1-Distill-Llama-70B 等大型模型。它基于思维链数据进行微调,其中包含数学、科学和编码方面的精选示例。这使得它非常适合在以下场景中使用:
- 内存和计算资源受限的环境
- 对延迟敏感的应用
- 需要多步推理和逻辑的任务
在本教程中,我们将向您展示如何使用 BentoML 在云端自托管 Phi-4-reasoning 作为私有 API。
设置
我们已将部署 Phi-4-reasoning 所需的一切都放在这个 GitHub 仓库 中,其中包含使用 BentoML 和 vLLM 部署流行开源 LLM(如 DeepSeek-R1、Llama 4 和 Phi-4)的示例。
您可以使用此示例作为基础,并根据您的独特用例进行自定义。
-
克隆仓库并进入 Phi-4 文件夹
git clone https://github.com/bentoml/BentoVLLM.git cd BentoVLLM/phi4-14b-reasoning -
创建虚拟环境并安装依赖
python -m venv venv source venv/bin/activate # Recommend Python 3.11 pip install -r requirements.txt -
如果您拥有至少 80GB 显存的 GPU(例如 NVIDIA A100 80G),您可以在本地启动服务器
bentoml serve
您的模型现在可通过 https://:3000/ 访问,所有 API 规范将自动生成。
如果您的本地机器资源不足,请跳到下一节。
将 Phi-4-reasoning 部署到 BentoCloud
BentoCloud 是一个统一的 AI 推理平台,用于构建和扩展 AI 系统,而无需管理基础设施。您可以在 BentoCloud 的托管计算资源中运行任何模型,或者自带云 (Bring Your Own Cloud),并将模型部署到您的私有 AWS、GCP 或 Azure 账户、NeoCloud 以及本地环境中。
入门指南
-
注册 BentoCloud 并登录。
bentoml cloud login -
部署模型并可选地设置名称。
bentoml deploy -n <your_deployment_name> -
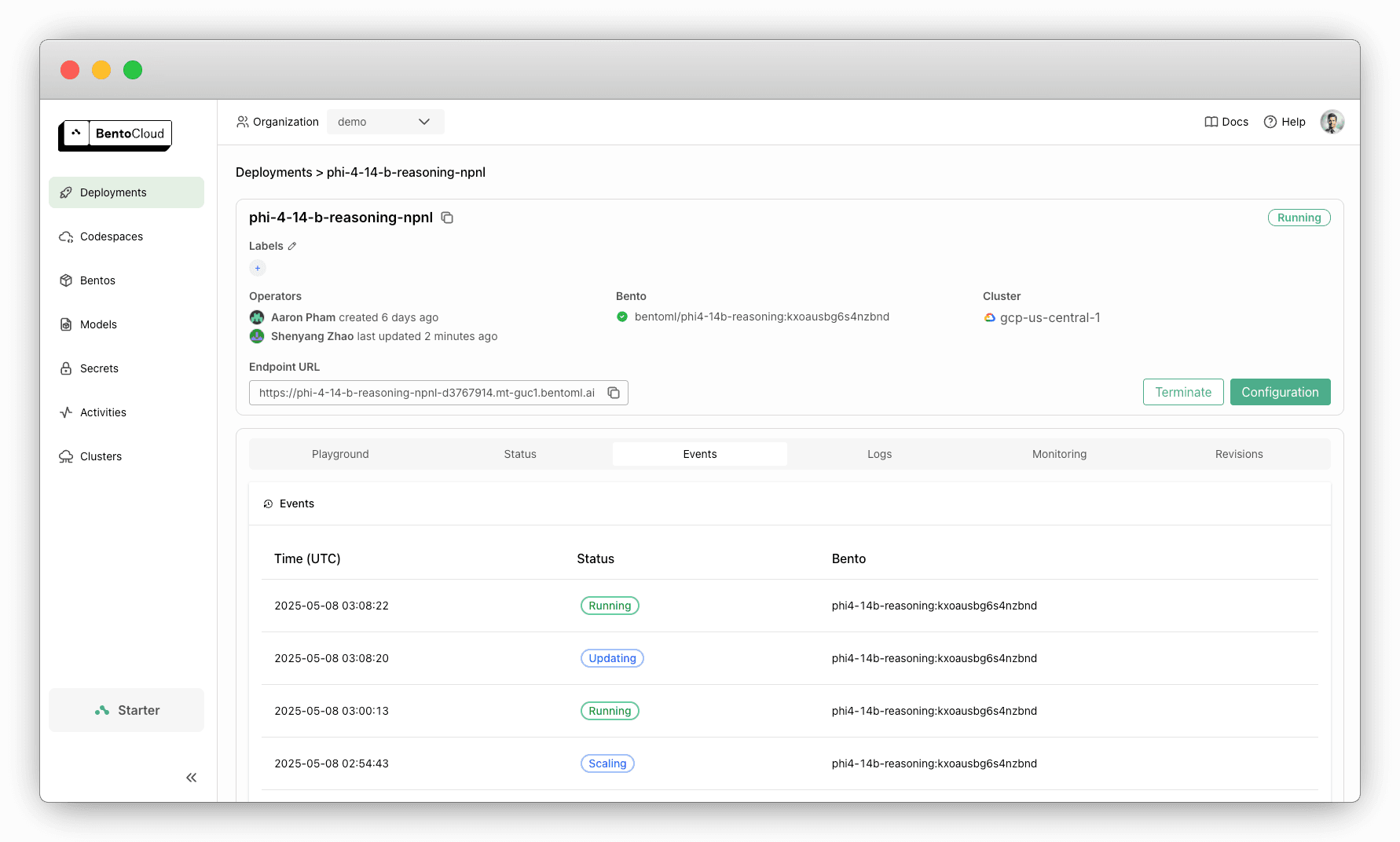
等待部署启动并运行。您可以这样检查部署状态:
import bentoml status = bentoml.deployment.get(name="<your_deployment_name>").get_status() print(status.to_dict()["status"]) # Example output: deploying -
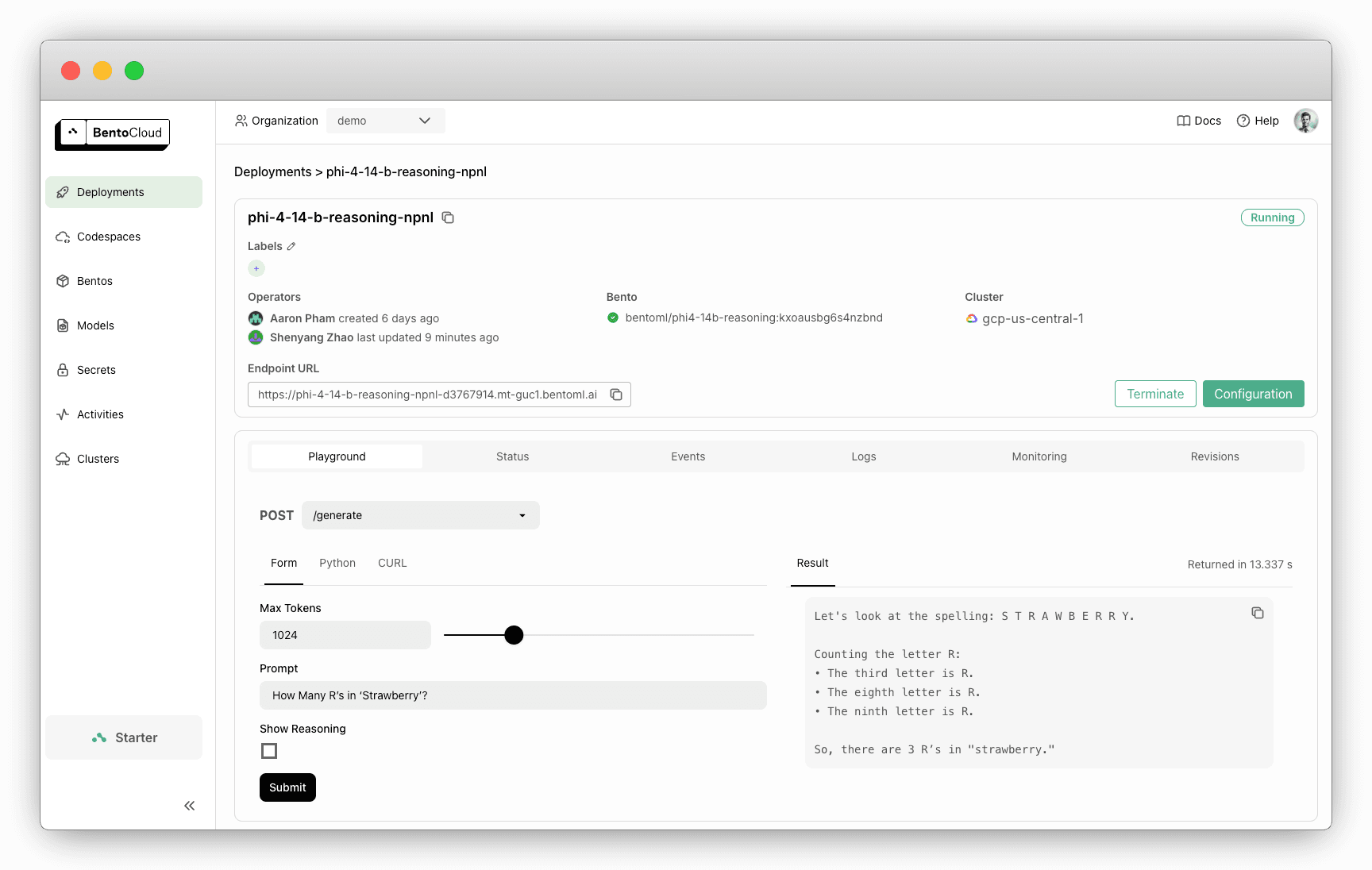
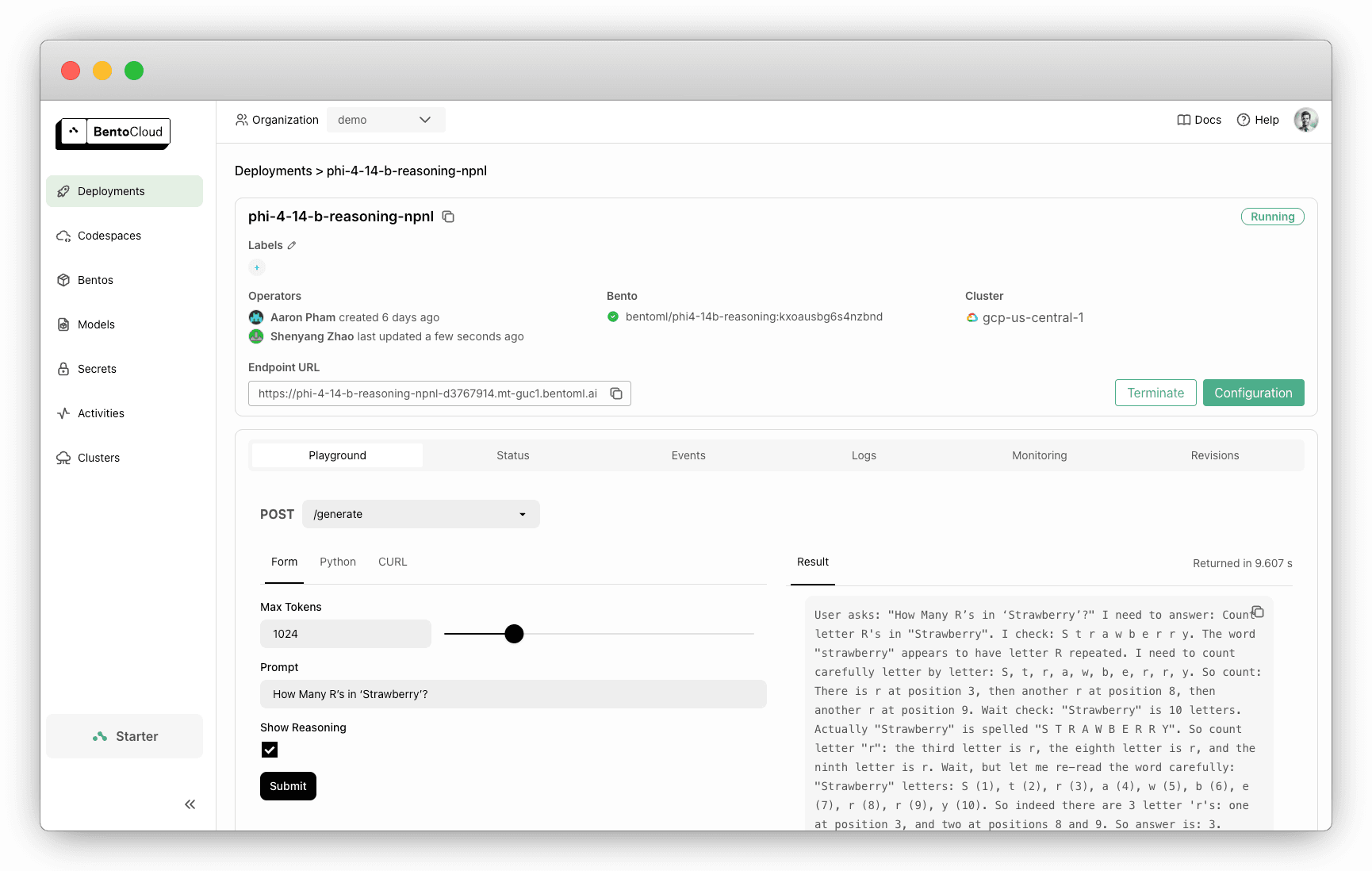
部署准备就绪后,在 BentoCloud 控制台上与其交互。选中Show Reasoning 将显示模型的推理步骤。
调用兼容 OpenAI 的 API
本项目公开了一个兼容 OpenAI 的 API,便于集成。
-
首先检索您的部署端点
bentoml deployment get <your_deployment_url> -o json | jq ."endpoint_urls"[0] # Example: "https://phi-4-example-bento-d1234567.mt-guc1.bentoml.ai" -
以下是使用
openaiPython SDK 的示例。请务必替换基本 URL。from openai import OpenAI client = OpenAI( base_url='https://phi-4-example-bento-d1234567.mt-guc1.bentoml.ai/v1', api_key='na' # set to your BentoCloud API token when endpoint protection is enabled ) # Use the following func to get the available models # model_list = client.models.list() # print(model_list) chat_completion = client.chat.completions.create( model="microsoft/Phi-4-reasoning", messages=[ { "role": "user", "content": "How many R's in 'Strawberry'?" } ], stream=True, ) for chunk in chat_completion: # Extract and print the content of the model's reply print(chunk.choices[0].delta.content or "", end="")
扩展部署
默认情况下,您的部署只有一个副本。要根据实时流量扩展它,请运行
bentoml deployment update <your_deployment_name> --scaling-min 0 --scaling-max 5 # Set your desired count
您也可以在Configurations页面配置扩展。
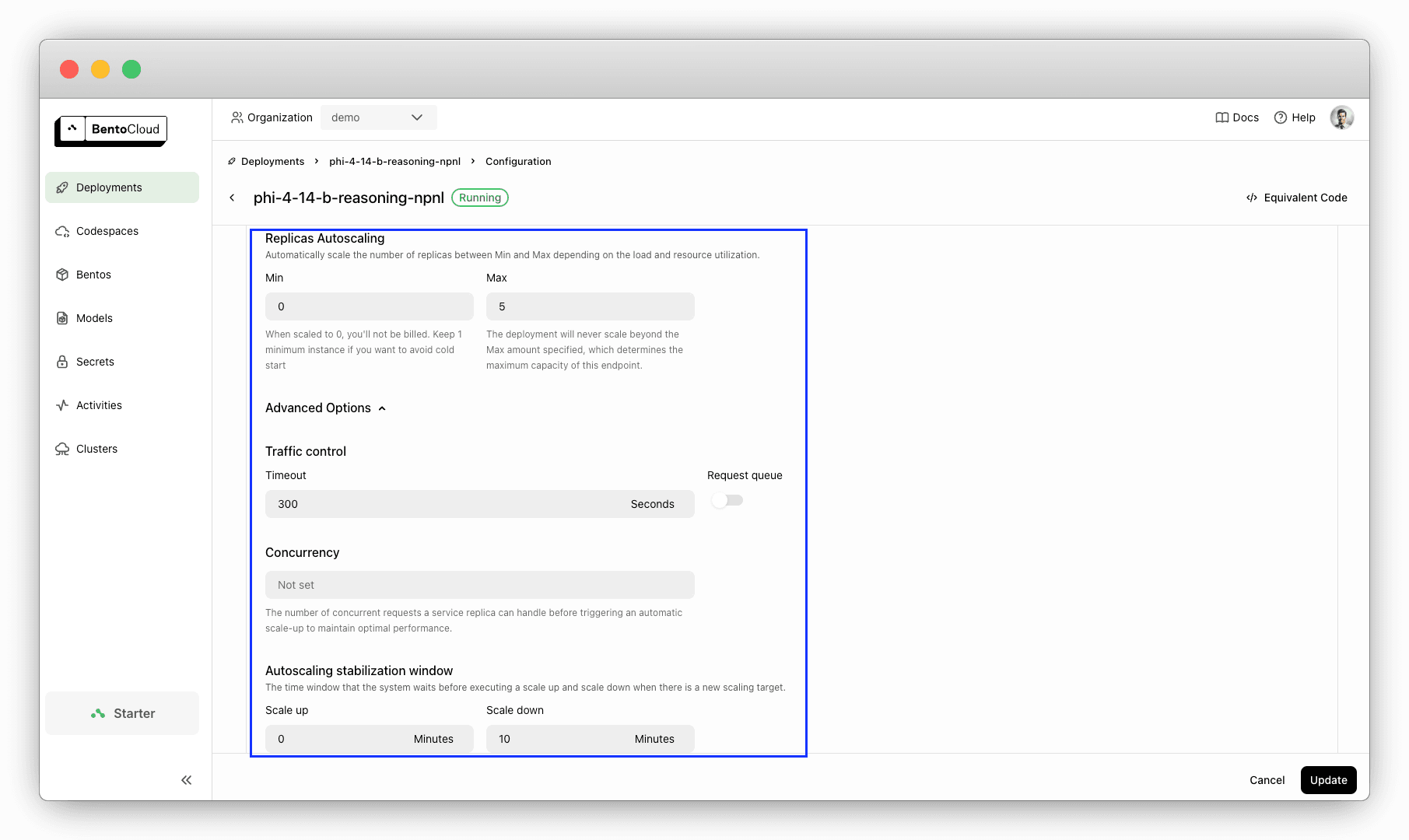
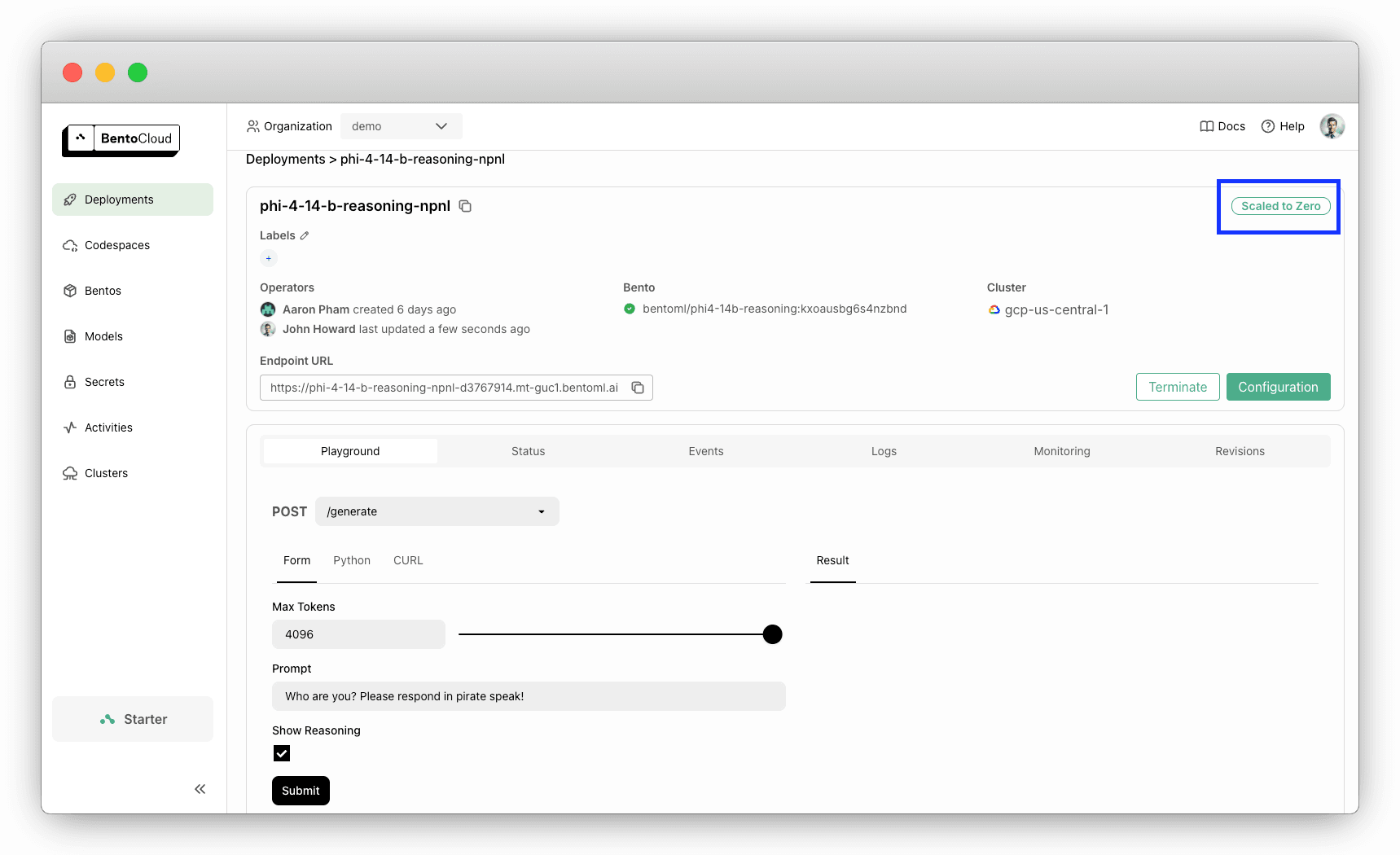
将最小副本数设置为 0 对于在空闲期间避免不必要的成本非常有用。当请求到来时,部署会自动扩展。
更新部署
使用 BentoML 的好处之一是易于更新部署。想改进提示格式或更新推理逻辑?只需在本地修改代码(例如,service.py),然后推送更新
bentoml deployment update <your_deployment_name> --bento .
这会将您更新的代码重新部署到同一 URL。客户端无需进行更改。
监控性能
BentoCloud 提供内置的可观测性仪表盘,帮助您跟踪使用情况并及早发现问题。
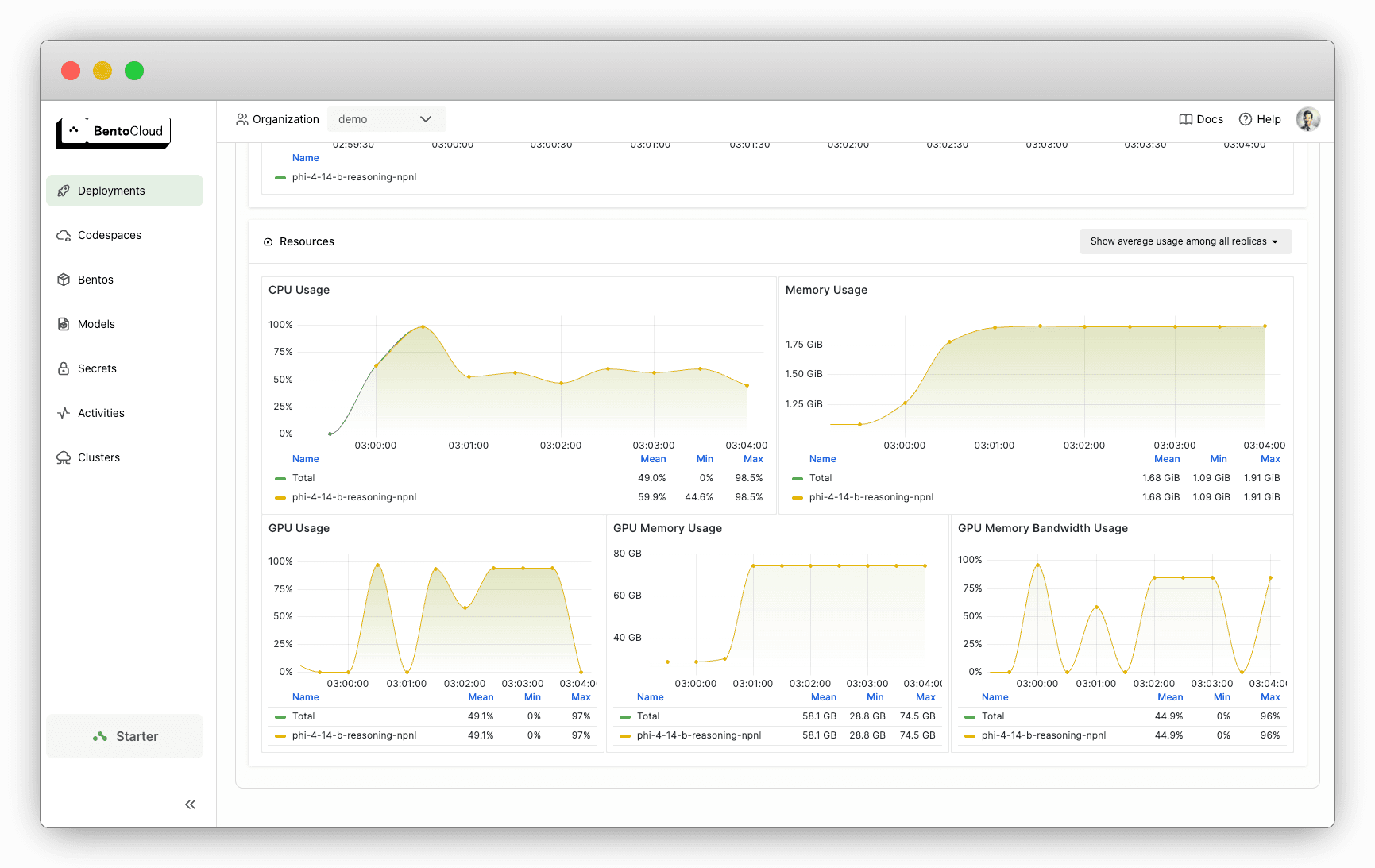
结论
Phi-4-reasoning 表明,智能的训练和微调策略可以使小型模型与巨头竞争。借助 BentoML,将这个强大的模型集成到您的工作流程中只需几个步骤。
立即开始,告别部署、扩展、监控或维护等基础设施难题。
- 注册 BentoCloud 以使用 Phi-4-reasoning 部署您的私有推理 API。
- 在 Slack 上加入我们的开发者社区,获取帮助、分享项目并保持最新状态。
- 还有问题吗?预约与我们的专家通话。