如何在AI推理中克服GPU CAP定理
2025年4月29日 • 作者:杨超宇 和 Sherlock Xu
在我们的 2024 年 AI 推理基础设施调查中,有一个发现引人注目:企业正在努力解决 GPU 可用性和定价问题。这是为什么呢?
与训练不同,推理是由实时使用驱动的,通常具有突发性和不可预测性。它需要按需扩展:在正确的时间拥有正确数量的计算资源的能力。
当企业以训练的心态处理推理(例如,通过长期承诺锁定固定的 GPU 容量)时,他们很快就会遇到麻烦
- 过度配置导致 GPU 集群利用率不足、资源浪费和高成本。
- 配置不足意味着请求丢失、响应时间缓慢和用户体验差。
- 僵化的预算使企业陷入无法适应实际使用的固定支出模式。
在 BentoML,我们亲身经历了这种差距。我们的使命是使推理具有所需的扩展性、安全性和成本效益。
在我们与企业客户的合作中,我们确定了影响 AI 推理 GPU 策略的三个核心维度:控制(Control)、按需可用性(Availability)和价格(Price)。在这篇博文中,我们将探讨为什么难以同时满足这三个方面,以及 BentoML 如何助您实现这一目标。
概念
让我们先看看这三个维度意味着什么。
控制(Control)
控制意味着在遵守监管要求的同时,对您的模型和数据拥有完全所有权。
推理工作负载通常直接与敏感的企业系统交互。常见的用例包括依赖大量专有数据的 AI 代理、RAG 管道和自主副驾驶。这些应用程序可能会访问机密文档、内部 API 和客户记录。这使得数据隐私极为重要。
为了保护数据,企业必须在他们控制的安全环境中运行推理工作负载,例如本地 GPU 集群或虚拟私有云网络。
在许多行业中,合规性是法律要求。GDPR 等监管框架要求将数据和模型保留在特定区域或数据中心内。对于医疗保健、金融和政府等行业,即使是暂时暴露于外部基础设施也可能是不可接受的。
按需可用性(On-demand availability)
按需可用性是指根据实时工作负载动态扩展或缩减 GPU 资源的能力。这种灵活性至关重要,因为 AI 推理工作负载很少保持一致。流量模式在一整天、一周或产品生命周期中波动。
当使用量增长时(例如,更多用户与您的产品互动),您需要配置更多 GPU 以维持可靠的性能。否则,您的产品质量会下降,导致服务故障。
当流量下降时(例如,在非高峰时段),您不会想继续为空闲容量付费。释放未使用的计算资源对于控制基础设施成本至关重要。
如果没有真正的按需可用性,企业将被迫在过度配置和配置不足之间做出选择。这两种情况都不可持续。
价格(Price)
当企业推出 AI 产品时,价格并非总是首要考虑因素。然而,随着推理工作负载的增长,GPU 的成本很快成为最大的基础设施开销之一。
在这种情况下,价格指的是 GPU 计算的单位成本,而不是总拥有成本(TCO)的全部。此成本会根据您运行推理工作负载的位置和方式而显著不同。
GPU CAP 定理:为什么总是有权衡
在 GPU 基础设施提供商中,我们看到上述三个要求之间存在反复出现的权衡。我们称之为 GPU CAP 定理。这意味着 GPU 基础设施无法同时保证控制(Control)、按需可用性(Availability)和价格(Price)。
下面详细介绍常见 GPU 基础设施选项的不足之处

超大规模云服务商(Hyperscaler)
AWS 和 GCP 等超大规模云服务商深受企业信任。它们提供广泛的区域访问、成熟的工具和集成服务。许多企业在其私有云账户中运行关键工作负载,并受益于其强大的安全功能。
然而,超大规模云服务商上的 GPU 成本非常高。虽然技术上支持按需配置,但实际可用性不稳定。在需求高峰期,等待时间可能从几分钟延长到几小时。
新型云服务商(NeoCloud,无服务器)
Modal 和 RunPod 等无服务器新型云平台提供了极佳的按需可用性,具有弹性扩展和简化部署的特点。
话虽如此,这些平台通常是多租户的,对于工作负载运行位置或数据处理方式缺乏可见性。对于受监管行业的企业来说,这种缺乏控制和透明度是一个重大问题。
新型云服务商(NeoCloud,长期承诺)
在新型云服务商中,CoreWeave 等提供商通过长期合约提供了更便宜的解决方案。它们允许企业获得折扣费率和更可预测的定价。在这种情况下,通过隔离的单租户环境,控制程度也得到了提高,类似于本地解决方案。
然而,由于 GPU 资源是预留的,您牺牲了按需可用性。
本地数据中心
构建和管理您自己的本地 GPU 集群提供了最高级别的控制。您对硬件和网络拥有完全所有权,并且可以设计您的基础设施以满足严格的合规性和数据安全要求。
但这会带来显著的成本和复杂性。您需要负责采购、安装、维护和内部运营。此外,您放弃了按需可用性。添加 GPU 意味着漫长的采购周期和物理部署延迟。
在考察了这些选项后,我们发现它们都无法完全满足这三个基本要求。
BentoML:在不妥协的情况下扩展 AI 推理
在 BentoML,我们认为企业应对其计算资源拥有完全所有权和灵活性,特别是对于任务关键型 AI 产品。他们应该能够在不牺牲数据安全或性能的情况下,控制推理工作负载的运行位置、在需要时扩展容量并优化成本。
这种理想状态被称为计算主权(Compute Sovereignty)。实现它的关键在于能够在本地、新型云服务商、多区域和多云环境中,按自身条件分配、扩展和管理 GPU 计算资源的能力。
统一计算架构(Unified compute fabric)
BentoML 提供了一个统一计算架构。它本质上是一个编排和抽象层,使企业能够跨以下环境部署和扩展推理工作负载:
- 本地 GPU 集群
- 自备云(BYOC,包括新型云服务商、多云和多区域设置)环境
全部通过一个集成的控制平面实现。
使用 BentoML 部署 AI 推理服务时,您将获得可由上述任何基础设施选项组合中的 GPU 资源支持的 API 端点。
以下是它在实践中的工作方式
- 在需要时自动溢出。如果您的本地集群(或新型云服务商长期承诺)容量不足,BentoML 可以无缝地将流量溢出到云 GPU。这确保您在扩展时始终拥有足够的计算能力。
- 动态配置和路由。在您的云账户中,BentoML 会跨您预先配置的最可用和最具成本效益的区域动态配置 GPU。您可以在不同的提供商上运行相同的模型和推理代码,且操作工作量极小。这确保了真正的按需可用性。
- 混合工作负载实现成本优化。BentoML 使您能够将长期 GPU 承诺(来自本地或新型云服务商)与按需和 Spot GPU 容量混合使用。这意味着您可以使用低成本的预留 GPU 来处理基线工作负载,并在仅需要时灵活地溢出到云 GPU。这使得成本可预测,同时不牺牲可扩展性。
- 完全控制模型和数据。对于有严格安全和合规性要求的组织,BentoML 提供自备云(BYOC,Bring Your Own Cloud)并支持本地部署。这意味着您的推理工作负载始终保留在您的 VPC 或数据中心内,绝不在共享基础设施上运行。
客户案例
以下两个示例展示了企业如何使用 BentoML 在不同环境中扩展 AI 推理。在这两种情况下,客户端体验保持一致。应用程序只需调用 BentoML 暴露的相同 API 端点。所有的扩展、路由和基础设施变更都在幕后发生,不影响用户体验。
示例一
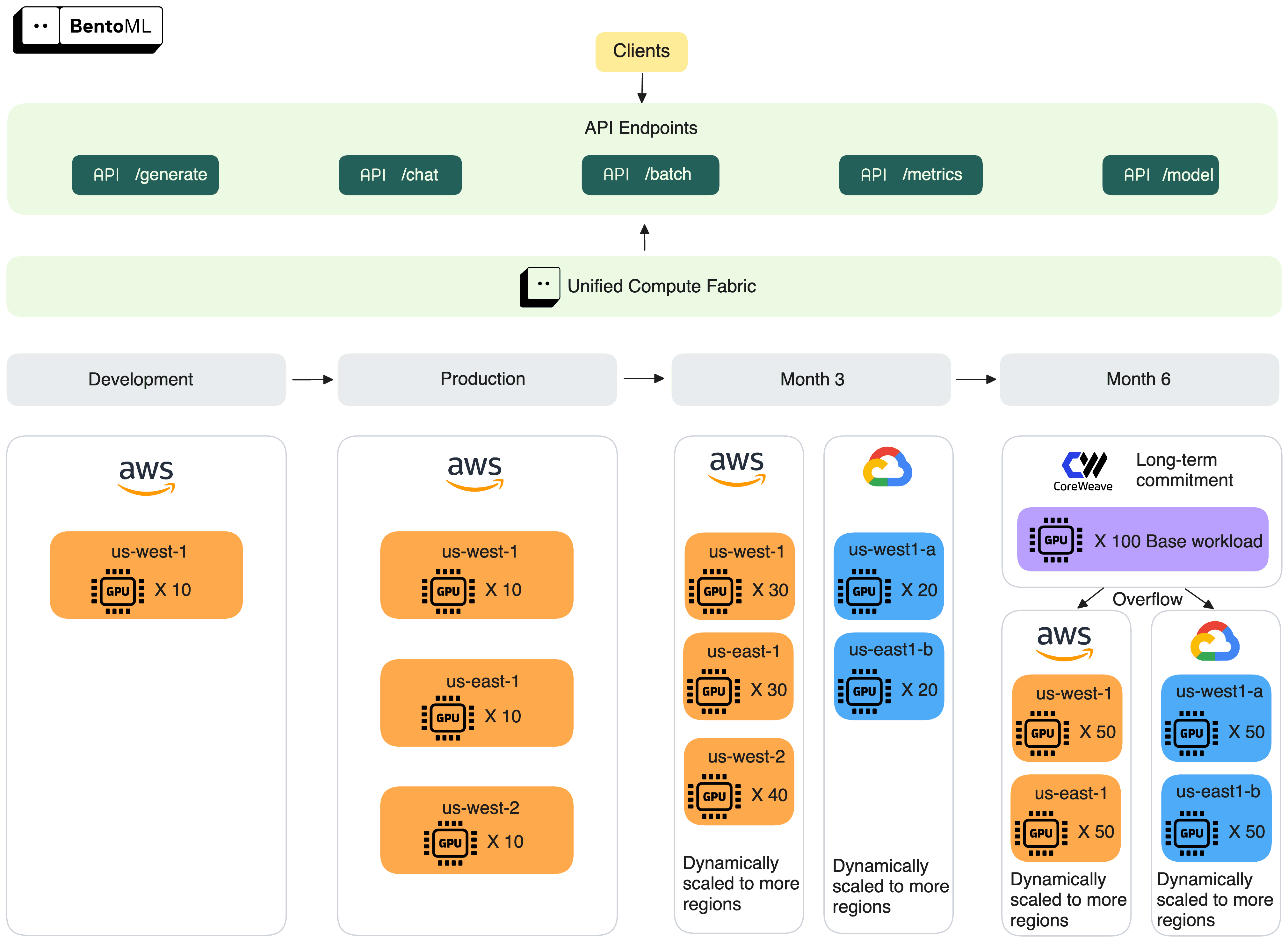
从单一 AWS 区域开始,该客户扩展到多个区域和云。到第 6 个月,他们通过长期 GPU 承诺锚定其基础工作负载,并使用 BentoML 将溢出流量扩展到不同云提供商。
示例二
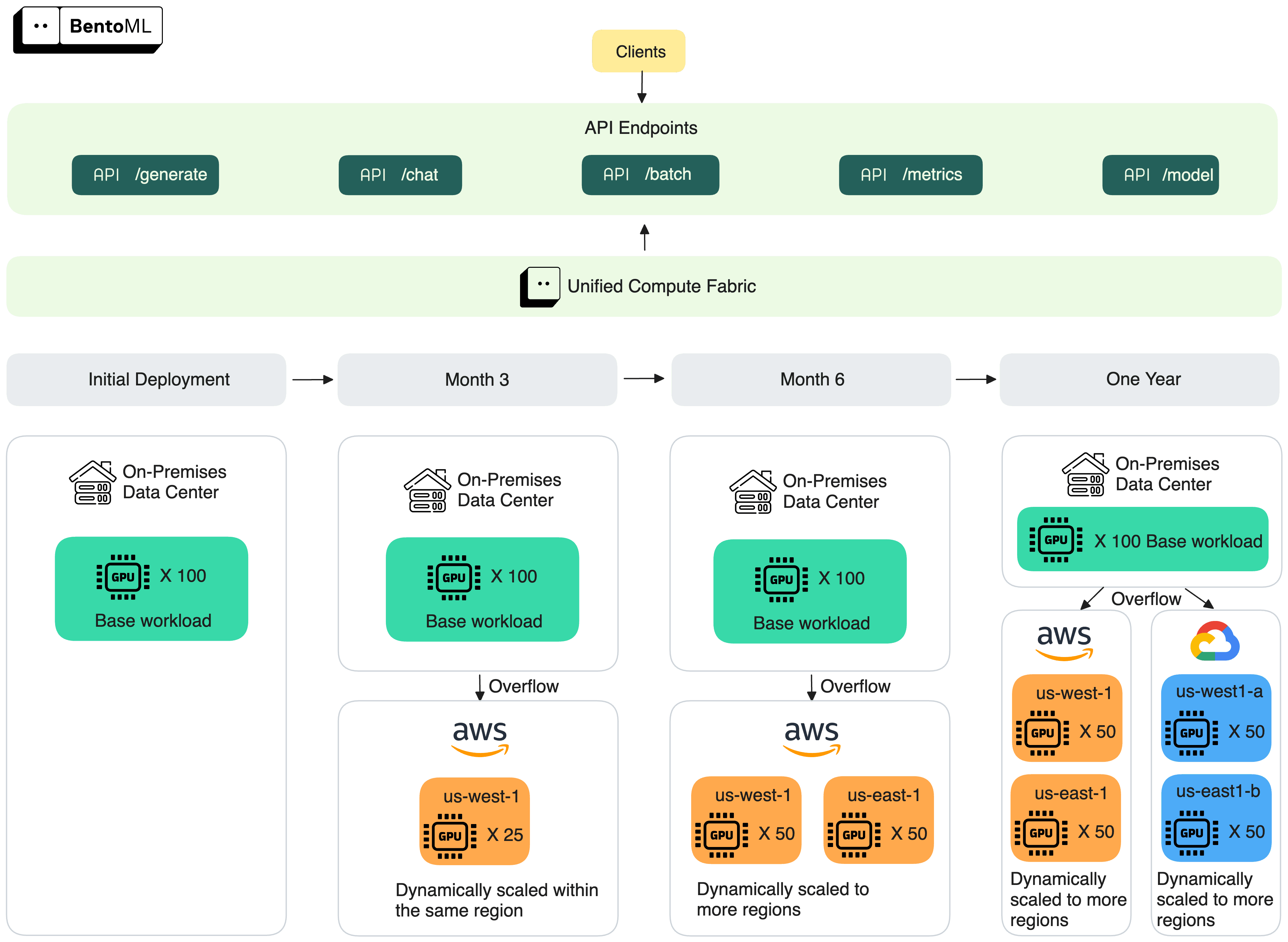
该客户从一个拥有 100 个 GPU 的本地集群开始。随着需求的增长,BentoML 将流量溢出到 AWS,并跨区域扩展,最终覆盖多个云。
结论
随着 AI 采用加速,推理基础设施必须发展以满足对安全性、扩展性和成本效益不断增长的需求。GPU CAP 定理明确指出:现有解决方案迫使企业做出妥协。
在 BentoML,我们认为您无需妥协。我们的统一计算架构为您提供所需的控制、按需可用性和价格灵活性,使您能够按照自己的条件大规模运行推理。
如果您正面临 GPU 基础设施方面的挑战,我们很乐意听取您的意见
- 与我们的专家交流,探索 BentoML 如何支持您的特定用例
- 加入我们的 Slack 社区,与其他构建者联系并与我们的团队分享反馈
- 注册我们的统一推理平台以开始使用