使用 BentoML 安全私密地部署 DeepSeek
2025 年 2 月 14 日 • 作者:Sherlock Xu
2025 年初,DeepSeek 的横空出世,在 AI 领域引发了巨变。其第一代推理模型 DeepSeek-R1 在数学、编码和复杂推理等多种任务上的性能媲美甚至超越了 OpenAI-o1 和 Claude-3.5 Sonnet 等领先模型。即使是32B 和 70B 的蒸馏模型也能与 OpenAI-o1-mini 等模型媲美。
然而,DeepSeek 也引发了关于数据隐私和安全的激烈讨论。当组织权衡各种选择时,许多人将**私有化部署**作为一种解决方案。幸运的是,DeepSeek V3 和 R1 都开源并允许商业使用。这意味着您可以在自己的安全环境中构建一个完全私有、定制化的 ChatGPT 级别应用。
在BentoML,我们帮助企业使用任何模型在任何云上安全地构建和扩展 AI 应用。在这篇博客文章中,我将解释 BentoML 如何帮助您私有化部署 DeepSeek。以下是我们的解决方案提供的功能:
- 部署在您私有 VPC 内、适用于任何云提供商(例如 AWS、GCP 和 Azure)或本地环境的专属 AI API
- 完全控制您的模型和数据资产
- 为高性能 AI 推理优化的快速且可扩展的基础设施
- 灵活选择跨云提供商的最佳 GPU 定价和可用性
- 支持所有 DeepSeek 变体的自定义代码和推理后端(例如 vLLM 和 SGLang)
如果您有任何疑问,请联系我们的专家获取个性化指导。加入我们的 Slack 社区,了解 DeepSeek 私有化部署的最新见解。
为什么 AI 团队正在转向私有化部署
乍一看,使用 DeepSeek 构建应用最简单的方法是直接调用其 API。虽然这种方法似乎是进入市场的最快途径,且基础设施开销最小,但这种便利伴随着重大的权衡。
数据隐私顾虑
调用 DeepSeek API 意味着将**私密的、商业敏感的数据**发送给第三方。对于有合规和隐私要求的受监管行业的组织来说,这通常是不可接受的选择。通过私有化部署,您可以完全拥有您的数据,确保数据保留在您的基础设施内,并符合行业法规和内部安全策略。
有限的定制能力
使用标准 API 意味着您与其他所有人使用相同的设置。没有灵活性为您的特定用例定制推理过程,这意味着没有竞争优势。例如,您无法:
- 为您的特定用例调整延迟-吞吐量权衡
- 利用前缀缓存或其他高级优化
- 针对长上下文或批量处理进行优化
- 强制结构化解码以确保输出遵循严格的模式
- 使用您自己的专有数据对模型进行微调
不可预测的性能和定价
共享 API 端点会带来一些操作上的麻烦:
- 速率限制和节流:如果使用量激增,您的请求可能会变慢甚至被阻止。
- 中断:API 是一个黑匣子;当它停机时,您的应用也会停止工作。
- 价格不确定性:DeepSeek 最近因其 V3 模型需求激增而调整了 API 定价。这凸显了依赖托管 AI API 的主要风险,因为您的成本可能在一夜之间毫无预警地上涨。
这些问题并非 DeepSeek 所独有。它们适用于所有托管 AI API 提供商,包括 OpenAI 和 Anthropic。有关权衡的详细信息,请参阅我们的博客文章《无服务器与专属 LLM 部署:成本效益分析》。
另一种选择是什么?通过在您自己的基础设施上私有化部署 DeepSeek(或任何其他开源模型)来掌控一切。
私有化部署 DeepSeek 的挑战
部署和维护像 DeepSeek 这样的模型需要大量的工程精力。以下是 AI 团队在私有环境中运行 DeepSeek 时面临的关键挑战:
GPU 可用性和定价
像 V3 和 R1 这样的 DeepSeek 模型规模巨大,拥有 6710 亿参数。运行这些模型需要 8 个配备 141GB 内存的 NVIDIA H200 GPU,这些 GPU 既稀缺又昂贵。
这些顶级 GPU 的有限可用性使得高效扩展变得困难。例如,如果您依赖按需 GPU 实例,您可能难以获得所需的容量。如果您预先配置它们以确保可用性,成本可能很快变得过高。
虽然您可以选择 DeepSeek 的小型蒸馏版本以降低硬件要求,但这可能意味着在某些任务上的性能会受到影响。
基础设施复杂性和维护成本
私有化部署后,基础设施的责任转移到您的团队。例如:
- 集群管理:设置和维护您自己的基础设施。
- 监控和可观测性:实施系统以跟踪性能并确保平稳运行。
- 专业知识:聘请 MLOps 工程师或其他专家来管理和优化您的部署。
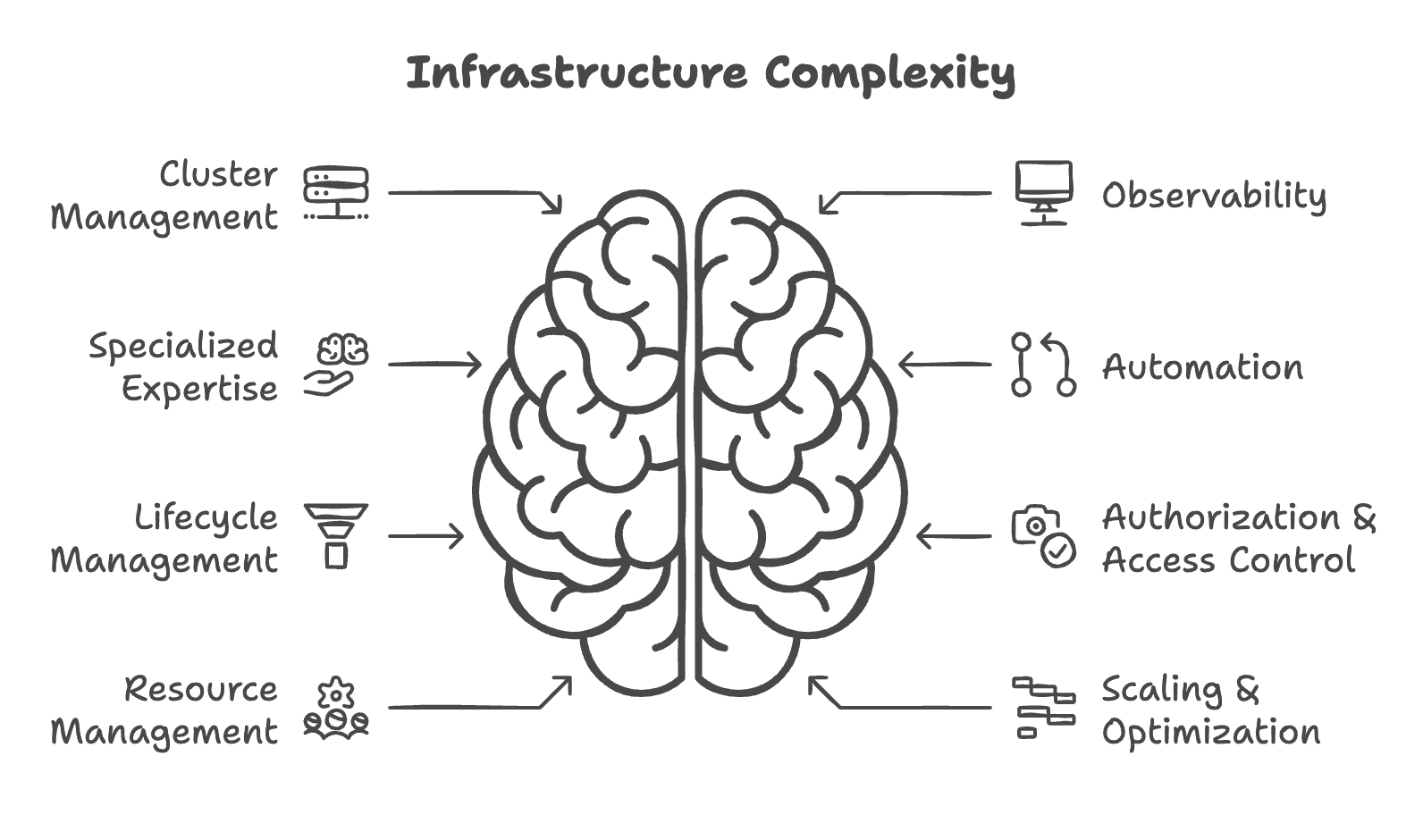
这些要求增加了运营开销,分散了您的团队在核心业务开发和创新上的精力。
缓慢的冷启动
如果没有高度可扩展和优化的基础设施,启动时间可能会非常慢。像 DeepSeek R1 这样的大模型需要大量时间来拉取容器镜像和加载模型权重。为了避免性能问题,您可能需要过度配置 GPU 实例。如上所述,这将推高云成本,使得扩展效率低下且昂贵。
BentoML 如何解决 DeepSeek 部署挑战
在 BentoML,我们让您轻松**使用任何模型私有化部署 AI 应用**,同时确保完整的数据隐私。让我们看看我们的解决方案如何应对前面讨论的每个挑战。
多云支持
BentoML 让您可以为您的用例选择最具成本效益和可用性的硬件。具体来说,您可以:
- 在所有云提供商(例如 AWS、GCP 和 Azure)、GPU 云提供商(例如 Lambda Labs 和 CoreWeave)以及本地基础设施上部署 DeepSeek。
- 访问各种 GPU(例如 A100、H100 和 H200),满足不同的推理需求。
- 根据实时定价、性能和可用性,选择最佳云区域和提供商,优化 GPU 开支。
这种灵活性确保您的 AI 工作负载始终获得最佳的性能成本比。
BYOC 让您无需承担基础设施负担
BentoML 的 BYOC(Bring Your Own Cloud,自带云)选项在托管服务和安全性之间实现了完美平衡:
- 完全托管平台,基础设施负担交由 BentoML 承担
- 在您的私有 VPC 内安全管理模型和数据
- 访问尖端的 AI 基础设施创新
- 专注于核心业务开发而非基础设施管理
请参阅我们的博客文章《从 BYOC 到 BentoCloud:集隐私、灵活性和成本效益于一体》了解更多信息。
支持规模缩容至零的超快速自动扩缩容
BentoML 通过优化的模型下载和加载策略加速部署。这大大缩短了冷启动时间,并实现了快速扩缩容和高效流式传输。此外,它还支持将副本数缩容至零,在低需求时期降低成本,同时不影响性能。
请参阅我们的博客文章《大规模部署 AI 模型》了解更多信息。
使用 BentoML 部署 DeepSeek
BentoML 让您可以轻松**安全私密地部署 DeepSeek**,支持所有变体,包括 R1、V3 和蒸馏版本。您可以轻松配置推理优化、自定义后端,并定义您自己的业务逻辑。请访问BentoVLLM 代码仓库,查看如何使用 BentoML 和 vLLM 部署 DeepSeek 的示例项目。
代码准备好后,您可以将 DeepSeek 部署到 BentoCloud,这是我们用于构建和扩展 AI 应用的 AI 推理平台。部署后,您将拥有一个完全由您控制的**专属、兼容 OpenAI 的 API 端点**。
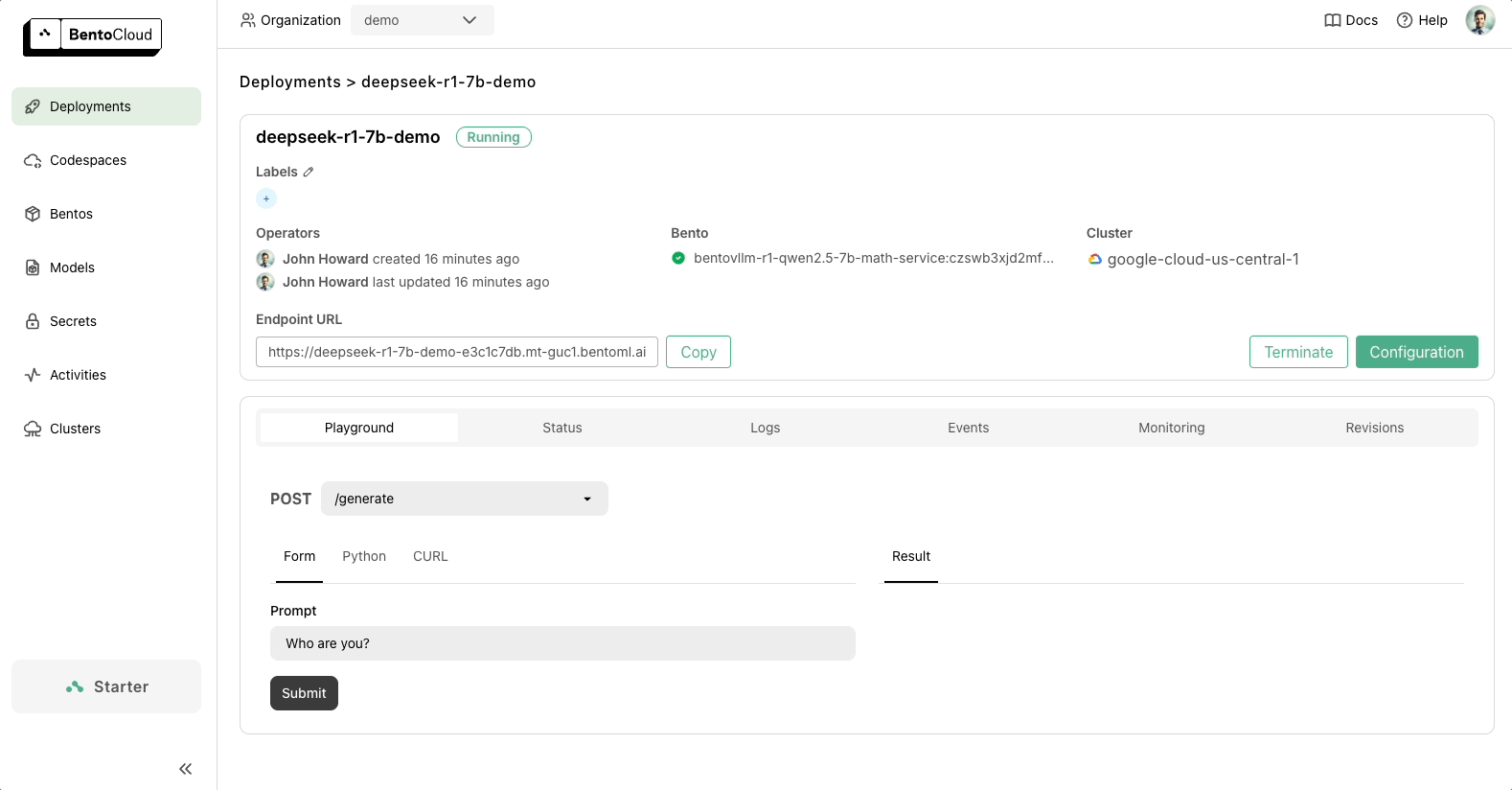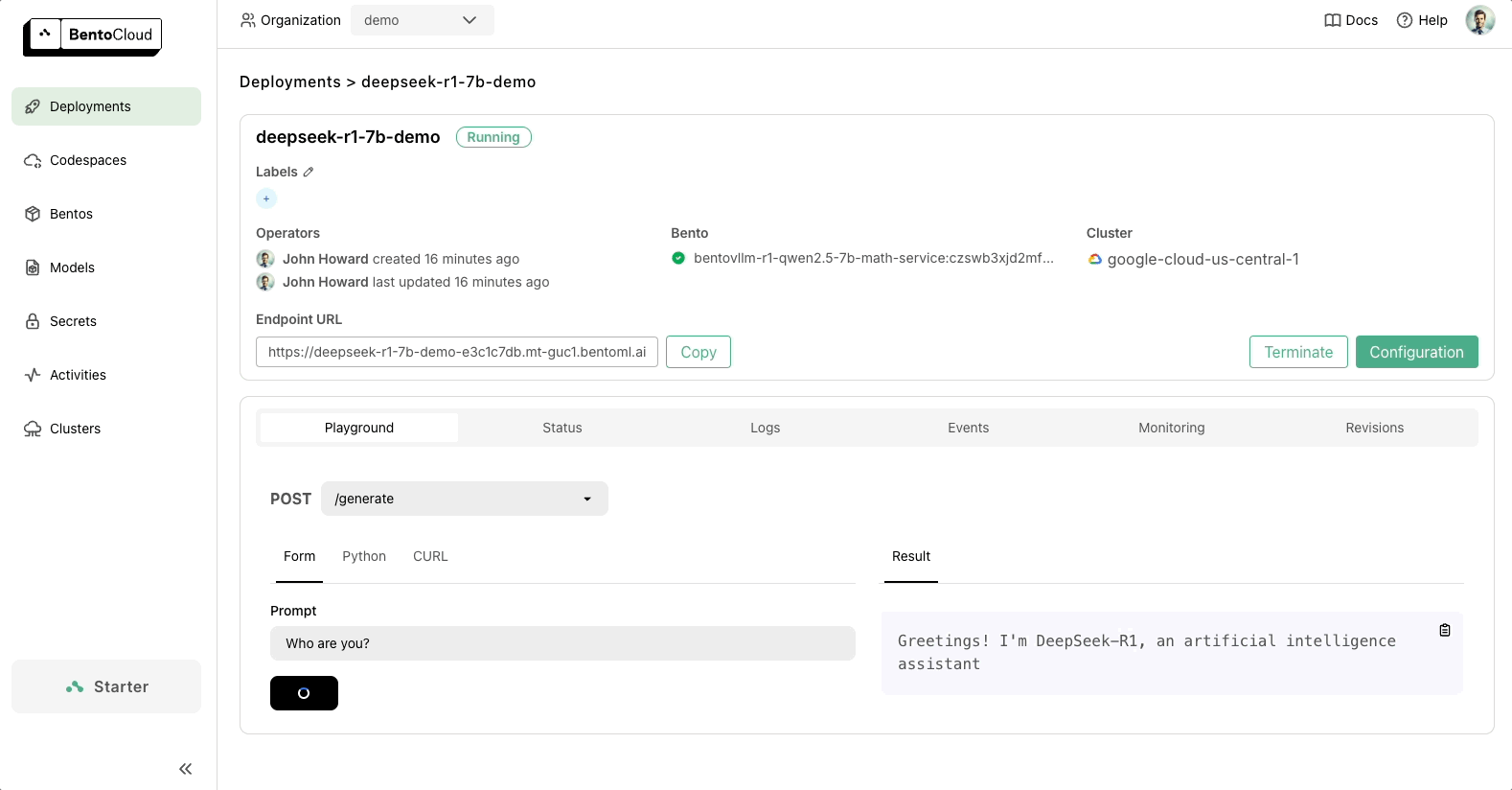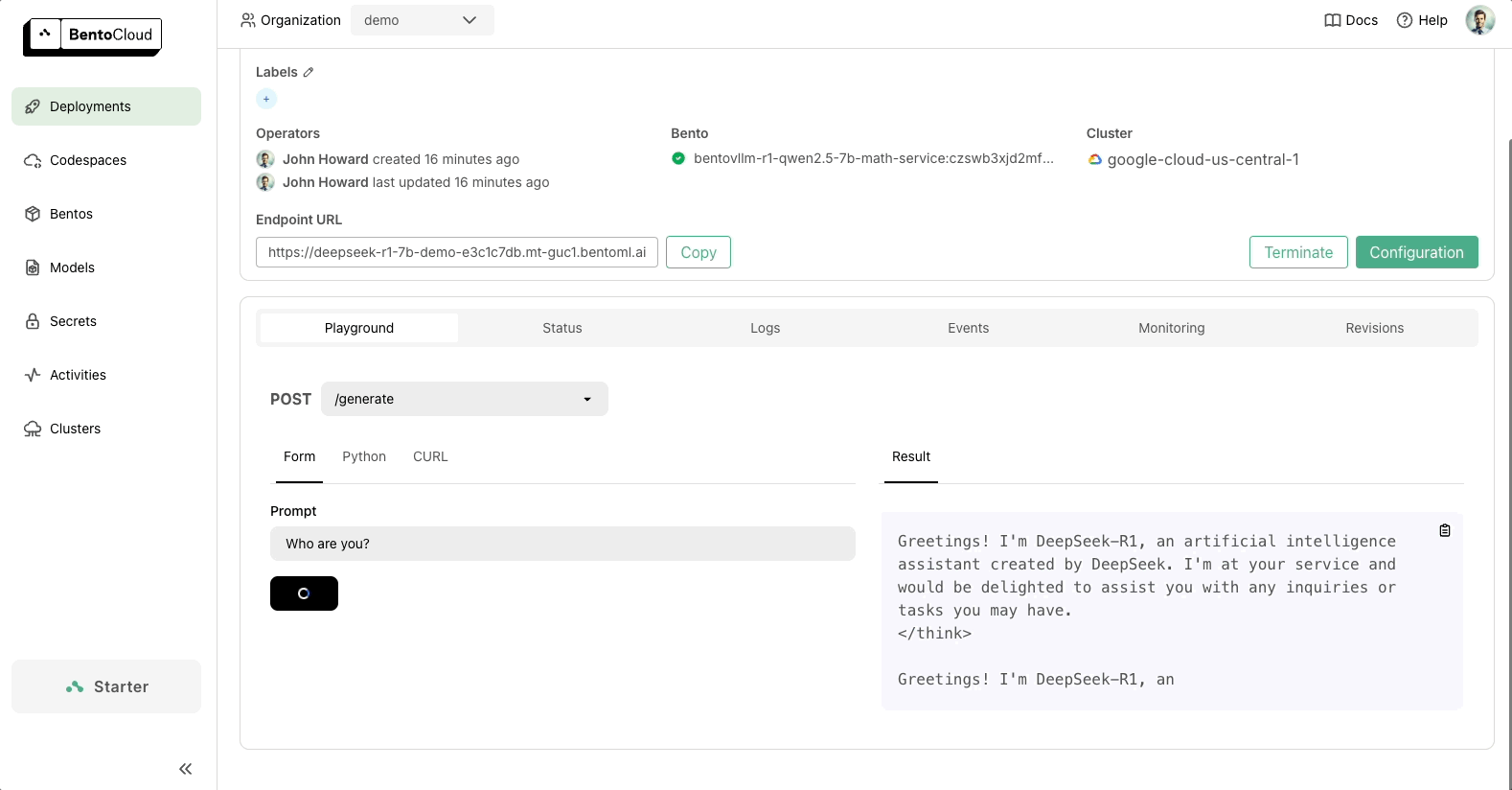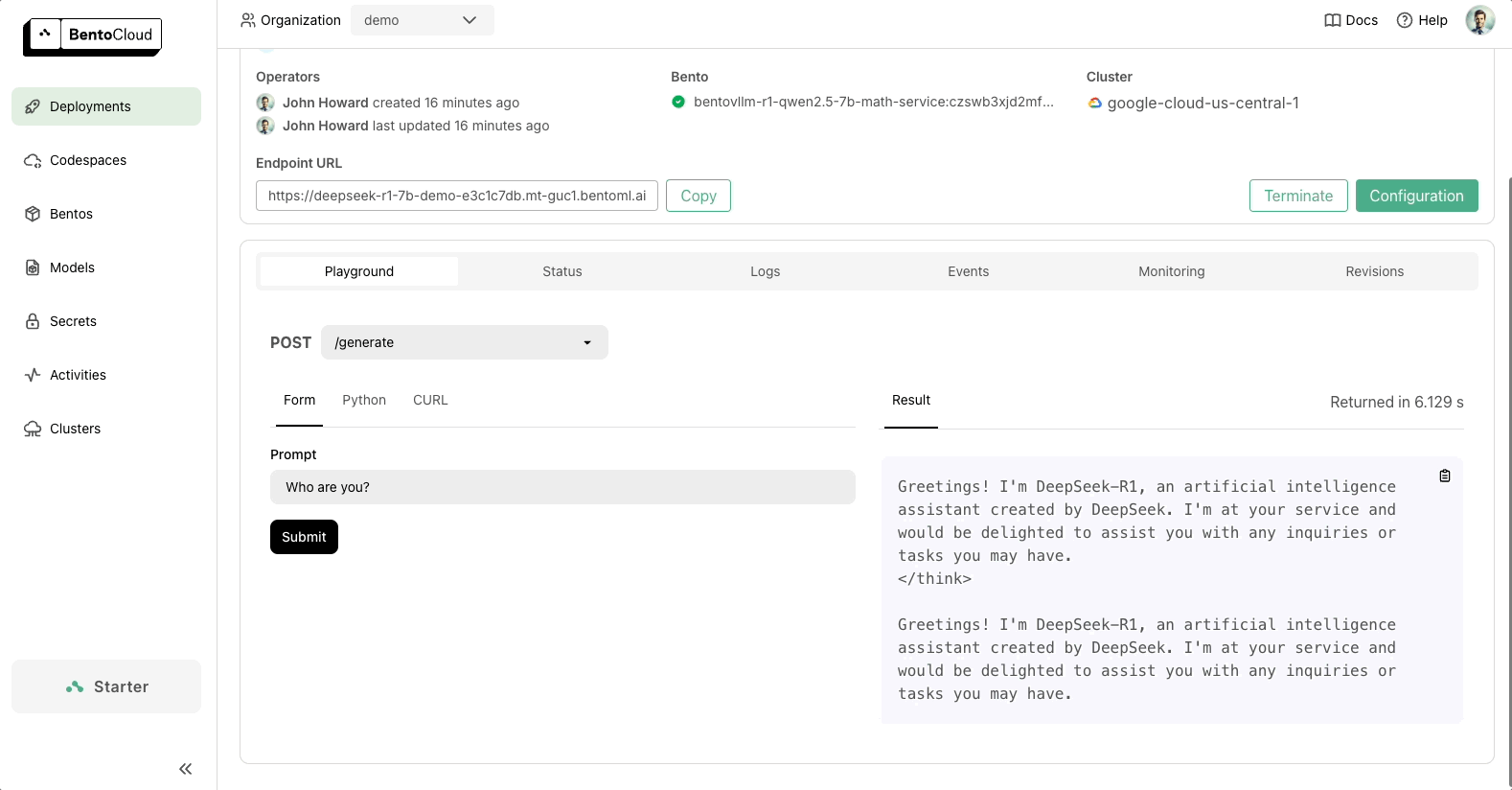
BentoML 提供了随您的需求扩展的灵活性,并确保您的 AI 基础设施面向未来。请查看以下资源了解更多信息:
- [博客] BentoCloud:在您的云中实现快速可定制的生成式 AI 推理
- [博客] 从 BYOC 到 BentoCloud:集隐私、灵活性和成本效益于一体
- 联系我们获取有关安全私有化 AI 部署的专家指导
- 加入我们的 Slack 社区,及时了解最新的 AI 发展动态
- 注册 BentoCloud,立即开始构建