DeepSeek 模型完全指南:从 V3 到 R1 及更远
更新于 2025 年 3 月 27 日 • 作者:Sherlock Xu
DeepSeek 已成为人工智能领域的重要参与者,不仅因其庞大的 671B 模型 V3 和 R1 受到关注,还因其一系列精炼版本而引人注目。随着人们对这些模型的兴趣日益增长,关于它们的差异、功能和理想用例的困惑也随之而来。
- “我应该使用哪个 DeepSeek 模型?”
- “R1 和 V3 有什么区别?”
- “R1-Zero 比 R1 更好吗?”
- “我真的需要一个精炼模型吗?”
这些问题在开发者论坛、Discord 频道和 GitHub 讨论中此起彼伏。说实话,产生困惑是情理之中。DeepSeek 的产品线迅速扩张,如果没有清晰的路线图,很容易迷失在技术术语和基准分数中。
在本文中,我们将剖析关键差异,并帮助您根据需求选择合适的模型。
DeepSeek-V3
让我们回到 2024 年 12 月,当时 DeepSeek 发布了 V3。这是一个专家混合 (MoE) 模型,拥有 6710 亿参数,每个 token 激活 370 亿参数。
如果您想知道专家混合是什么意思,它实际上是一个很酷的概念。本质上,这意味着模型可以根据手头的任务激活自身的不同部分。它不是一直使用整个模型,而是“挑选”适合该任务的专家。这不仅使其功能强大,而且效率很高。
DeepSeek-V3 最引人注目的地方或许是其训练效率。尽管模型规模庞大,但它仅需要 278.8 万 H800 GPU 小时,换算成训练成本约为 560 万美元。相比之下,训练 GPT-4 的成本估计在 5000 万至 1 亿美元之间。
DeepSeek-V3 Base 模型与 Chat 模型
DeepSeek-V3 有两个版本:Base 模型和 Chat 模型。
- Base 模型正如其名——基础模型。在其预训练阶段,它本质上是学习预测海量文本中的下一个词。创建这个 Base 模型后,DeepSeek 研究人员对其进行了两种不同的后训练流程,以创建具有不同功能的模型(从而产生了另外两个模型:DeepSeek-V3 Chat 模型和 R1)。
- Chat 模型(又称 DeepSeek-V3,是的,命名可能会引起混淆)经过了额外的指令微调和人类反馈强化学习 (RLHF),使其在对话中更加有用、无害和诚实。它在编码和数学等任务中表现出色,甚至可以与 GPT-4o 和 Llama 3.1 405B 等模型相媲美。
您可以在评估结果中查看它们详细的基准性能。
部署 DeepSeek-V3
DeepSeek-V3 Base 模型和 Chat 模型都是开源且可商业使用的。您可以自托管它们来构建您自己的 ChatGPT 级别应用程序。如果您正在寻求部署 DeepSeek-V3,请查看我们使用 BentoML 和 vLLM 的示例项目。
DeepSeek-R1
DeepSeek 并未止步于 V3。几周后,他们在 DeepSeek-V3-Base 的基础上又推出了两个新模型:DeepSeek-R1-Zero 和 DeepSeek-R1。
DeepSeek-R1-Zero:无监督学习
DeepSeek-R1-Zero 使用大规模强化学习 (RL) 进行训练,跳过了通常的监督微调 (SFT) 步骤。简单来说,它完全依靠自身学习推理模式,通过试错而非结构化指导来提升能力。
虽然结果显著,但也存在权衡。R1-Zero 偶尔会出现无休止的重复、可读性差甚至语言混杂的问题。
DeepSeek-R1:更完善的推理模型
为了弥补这些不足,DeepSeek 采用更复杂的、多阶段的训练流程开发了 DeepSeek-R1。这包括在应用强化学习之前,加入数千个“冷启动”数据点来微调 V3-Base 模型。最终的成果是 R1,该模型不仅保留了 R1-Zero 的推理能力,还在准确性、可读性和连贯性方面有了显著提升。
与为通用任务优化的 V3 不同,R1 是一个真正的推理模型。这意味着它不仅会给出答案,还会解释它是如何得出答案的。在响应之前,R1 会生成一步一步的思维链,这使其在以下方面特别有用:
- 复杂的数学问题求解
- 编程挑战
- 科学推理
- 代理工作流的多步规划
在性能方面,R1 在数学、编程和推理基准测试中可与OpenAI o1(也是一个推理模型,但不像 R1 那样完全公开思考 tokens)媲美甚至超越。这使其成为目前最强大的开源推理模型。
部署 DeepSeek-R1
R1 是 DeepSeek 聊天应用程序背后的引擎,许多开发者已开始将其用于私有化部署。如果您希望自行运行它,请查看我们使用 BentoML 和 vLLM 的示例项目。
使用 R1 时请记住以下技巧
- 避免使用系统提示词,确保所有指令都直接包含在用户提示词中。
- 对于数学问题,添加类似
Please reason step by step, and put your final answer within \boxed{}的指令。 - 请注意,R1 有时可能会跳过其推理过程(即输出
<think>\n\n</think>)。为鼓励进行充分推理,请在您的提示词中告诉模型以<think>\n开始响应。
在DeepSeek-R1 仓库中查看更多建议。
DeepSeek-V3 vs. DeepSeek-R1:您应该选择哪个?
DeepSeek-V3 和 DeepSeek-R1 是当今许多工程师的首选模型,但它们用途不同。如果您不确定哪个模型适合您的需求,这里有一个快速比较,帮助您决定
| 项目 | DeepSeek-V3 | DeepSeek-R1 |
|---|---|---|
| 基础模型 | DeepSeek-V3-Base | DeepSeek-V3-Base |
| 类型 | 通用语言模型 | 推理模型 |
| 响应风格 | 直接答案(例如,“答案是 42”) | 逐步推理(例如,“首先,计算 X... 然后 Y... 所以答案是 42”) |
| 参数量 | 6710 亿 (激活 370 亿) | 6710 亿 (激活 370 亿) |
| 架构 | MoE | MoE |
| 上下文长度 | 128K | 128K |
| 许可证 | MIT 和 模型许可证 | MIT |
| 最适合 | 内容创作、写作、翻译、通用问答 | 复杂数学、编码、研究、逻辑推理、代理工作流 |
| 标准 API 定价* (UTC 00:30-16:30) |
|
|
| 标准 API 定价* (UTC 00:30-16:30) | 输出 tokens 每百万 $1.10 | 输出 tokens 每百万 $2.19 |
* 定价基于 2025 年 3 月 6 日的数据,可能会随时间变化。DeepSeek 在每日 UTC 16:30-00:30 期间提供非高峰时段折扣。详情请查阅其API 文档。
简而言之,我建议您
- 如果您需要一个快速、通用的模型来处理写作、摘要、翻译或日常问答等任务,请选择 DeepSeek-V3。
- 如果您需要一个注重推理的模型来处理数学、编码、研究或任何需要逐步逻辑思考的任务,请选择 DeepSeek-R1。
DeepSeek-V3-0324
2025 年 3 月,DeepSeek 发布了一个强大的新更新:DeepSeek-V3-0324。虽然它使用与 DeepSeek-V3 相同的 Base 模型,但后训练流程得到了改进,吸取了 DeepSeek-R1 中 RL 技术的经验。这使得新模型具有更好的推理性能、编码技能和工具使用能力。在数学和编码评估中,DeepSeek-V3-0324 甚至优于 GPT-4.5。
如果您不需要完全详细的推理链(或者只是处理不复杂的推理任务),我推荐这个更新的版本,因为它比 V3 更快、更强大。
精炼版 DeepSeek 模型:将推理能力引入小型模型
虽然 V3 和 R1 令人印象深刻,但运行它们并非对所有人来说都实用。它们需要 8 块 NVIDIA H200 GPU,每块具有 141GB 显存。
这时,精炼版 DeepSeek 模型就发挥作用了。这些更小、更高效的模型将 R1 的推理能力带到了更易于访问的规模。DeepSeek 没有从头开始训练新模型,而是采取了一条巧妙的捷径
- 始于 Llama 3.1/3.3 和 Qwen 2.5 的 6 个开源模型
- 使用 R1 生成了 80 万个高质量推理样本
- 使用这些合成推理数据微调了小型模型
与 R1 不同,这些精炼模型仅依赖 SFT,不包含 RL 阶段。
尽管规模较小,这些模型在推理任务上表现出色,证明了大规模 AI 推理可以高效地进行精炼。DeepSeek 已经开源了所有六个精炼模型,参数范围从 15 亿到 700 亿。
但在我深入探讨各个模型之前,让我们快速了解一下促成这一切的技术:蒸馏。
什么是蒸馏
蒸馏是一种将知识从大型、强大的模型转移到小型、更高效模型的技术。小型模型不是在原始数据上训练,而是学习模仿大型模型的行为。
Geoffrey Hinton、Oriol Vinyals 和 Jeff Dean 的研究论文《Distilling the Knowledge in a Neural Network》提供了一个很好的类比。他们将蒸馏比作昆虫从幼虫到成虫的进化过程
- 幼虫阶段为生长而优化,尽可能多地吸收营养。
- 成虫阶段则注重效率,更快速、更精干,适应生存。
类似地,大型 AI 模型使用海量数据集和高计算能力进行训练,以提取深层知识。但在大规模部署时,需要更快、更轻便的模型。这就是蒸馏的作用所在。它将大型模型的智能压缩到小型模型中,使其在实际应用中更实用。
基于 Llama 和 Qwen 的精炼模型
现在,让我们仔细看看每个精炼模型。
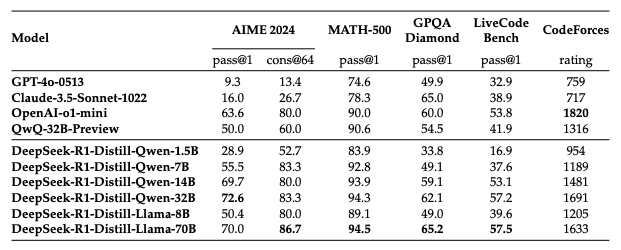
DeepSeek-R1-Distill-Qwen-1.5B
这是系列中最小的模型,具有不错的数学和推理能力。它在 AIME 和 MATH-500 上优于 GPT-4o 和 Claude-3.5-Sonnet,是轻量级问题解决的不错选择。然而,它在编码任务方面表现不佳,在 LiveCodeBench 上仅得 16.9 分,这意味着它不适合编程应用。
DeepSeek-R1-Distill-Qwen-7B
这是 1.5B 模型的一个升级版,在数学推理和通用问题解决方面提供了更强的性能。它在 AIME (55.5) 和 MATH-500 (92.8) 上得分不错,但在编码基准测试 (LiveCodeBench 37.6) 中仍然落后。
DeepSeek-R1-Distill-Llama-8B
该模型基于 Llama 3.1 架构,展现出强大的数学推理能力。它不仅在 AIME 和 MATH-500 上超越 GPT-4o 和 Claude-3.5-Sonnet,而且在 MATH-500 上表现非常接近 o1-mini 和 QwQ-32B-Preview。其编码性能显示出更好的竞赛编程技能,但仍未能与大型模型匹敌。
DeepSeek-R1-Distill-Qwen-14B
这是一个均衡的模型,提供强大的推理、数学和通用逻辑能力。对于那些需要在不增加高计算成本的情况下提高准确性的人来说,这是一个很好的折中方案。虽然编码性能不是最好的,但非常接近 o1-mini。
DeepSeek-R1-Distill-Qwen-32B
这是表现最好的精炼模型之一。凭借顶级的推理能力(AIME 得分 72.6,MATH-500 得分 94.3)和强大的 CodeForces 评分(1691),它是数学密集型应用、竞赛问题解决和高级人工智能研究的绝佳选择。
一个有趣的研究发现:DeepSeek 使用这个模型来比较蒸馏和 RL 在推理任务上的效果。他们测试了通过大规模 RL 训练的小模型是否能达到精炼模型的性能水平。
为了探索这一点,他们使用数学、编码和 STEM 数据训练 Qwen-32B-Base 超过 10,000 个 RL 步骤,从而得到了 DeepSeek-R1-Zero-Qwen-32B。

结论是,将强大的模型蒸馏到小型模型中效果更好。相比之下,使用大规模 RL 的小型模型需要巨大的计算能力,并且与蒸馏相比可能仍然表现不佳。
DeepSeek-R1-Distill-Llama-70B
这是最强大的精炼模型,基于 Llama-3.3-70B-Instruct(选择它是因其比 Llama 3.1 具有更好的推理能力)。在 MATH-500 上得分 94.5,它与 DeepSeek-R1 本身非常接近。它还在所有精炼模型中获得了最高的编码分数(LiveCodeBench 上得分 57.5)。
以下是对这六个精炼模型的高层次比较
| 模型 | 基础模型 | 最适合 | 推理能力 | 计算成本 |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 入门级推理,基础数学 | 💪💪 | 低 |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 中等级数学和逻辑任务 | 💪💪💪 | 中等 |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 中等级数学和逻辑任务,编码辅助 | 💪💪💪 | 中等 |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 高级数学和逻辑任务,问题解决,编码辅助 | 💪💪💪💪 | 中高 |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 复杂数学、逻辑和编码任务,问题解决,研究 | 💪💪💪💪💪 | 高 |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 复杂数学、逻辑和编码任务,问题解决,研究 | 💪💪💪💪💪 | 高 |
探索我们的示例项目,使用 BentoML 和 vLLM 部署这 6 个精炼模型。
超越 DeepSeek:社区驱动的创新
DeepSeek 点燃了开源创新的浪潮,研究人员和开发者以创造性的方式扩展其模型。以下是两个示例
- DeepScaleR-1.5B-Preview 是使用分布式 RL 从 DeepSeek-R1-Distill-Qwen-1.5B 微调的模型,旨在提升长上下文能力。它将 AIME 2024 的 Pass@1 准确率提高了 15%(43.1% 对 28.8%),甚至超越了 OpenAI O1-Preview——所有这些都仅用 15 亿参数实现。
- 来自 Berkeley AI Research 的Jiayi Pan 以不到 30 美元的成本成功复现了 DeepSeek R1-Zero 的推理技术。这在提高高级 AI 研究的可及性方面迈出了巨大一步。
这些社区努力表明了开源如何赋能研究人员和开发者创建更易访问且功能强大的 AI 解决方案。
下一步是什么
现在您已经熟悉了 DeepSeek 模型,您可能会考虑使用它们构建您自己的 AI 应用程序。乍一看,调用官方 DeepSeek API 似乎是最简单的解决方案;它提供了快速上市时间,且没有基础设施负担。
然而,这种便利性也伴随着一些权衡,包括
- 数据隐私和安全风险
- 有限的定制化(例如无法进行推理优化或使用专有数据进行微调等)
- 不可预测的行为(例如速率限制、服务中断、API 限制等)
随着组织权衡各种选项,许多组织正在转向私有化部署,以保持控制、安全和灵活性。
在BentoML,我们帮助企业使用任何模型在任何云上安全地构建和扩展 AI 应用程序。我们的 AI 推理平台 BentoCloud 允许您在任何云提供商或本地基础设施上部署任何 DeepSeek 变体,提供
- 在最具成本效益的区域访问多种 GPU
- 在您的私有 VPC 中灵活部署
- 具有快速冷启动时间的高级自动扩缩容
- 内置可观测性,提供 LLM 特定的指标
查看以下资源了解更多信息
- [博客] 使用 BentoML 安全私有地部署 DeepSeek
- [博客] BentoCloud:在您的云中实现快速且可定制的 GenAI 推理
- [博客] BYOC 到 BentoCloud:隐私、灵活性和成本效益集于一体
- 联系我们获取关于安全私有 DeepSeek 部署的专家指导
- 加入我们的 Slack 社区,随时了解最新的 AI 发展动态
- 注册 BentoCloud,立即部署您的定制 DeepSeek 驱动应用程序